A estatística descritiva organiza, resume e apresenta dados de forma informativa, sem fazer inferências além do que foi observado. É o ponto de partida obrigatório de qualquer análise: conhecer os dados antes de modelá-los.
Seus principais componentes são:
Medidas de tendência central: onde os dados se concentram
Medidas de dispersão: o quanto os dados se afastam do centro
Medidas de posição: localização relativa dentro da distribuição
Medidas de forma: assimetria e achatamento da distribuição
5.2 Medidas de tendência central
5.2.1 Média aritmética
A média aritmética é a soma de todos os valores dividida pelo número de observações:
\[\bar{x} = \frac{1}{n}\sum_{i=1}^{n}x_i\]
Propriedades:
Sensível a valores extremos - um único outlier pode distorcê-la significativamente
Única para cada conjunto de dados
Minimiza a soma dos quadrados dos desvios
Quando usar: dados quantitativos contínuos com distribuição aproximadamente simétrica e sem outliers extremos.
5.2.2 Mediana
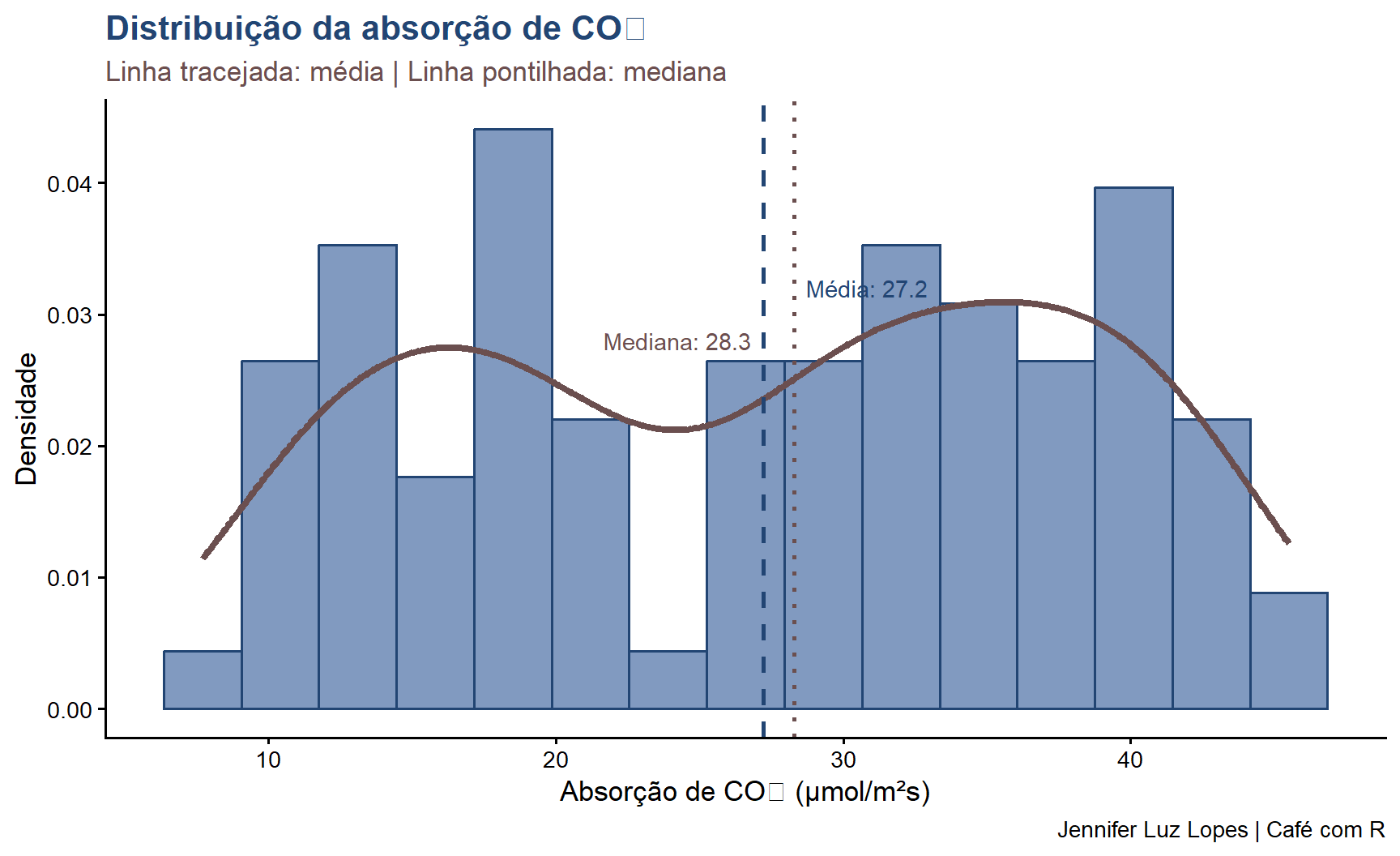
A mediana é o valor central do conjunto ordenado de dados. Metade das observações fica abaixo e metade acima.
Comparação média - mediana:
Relação
Interpretação
Média ≈ Mediana
Distribuição aproximadamente simétrica
Média > Mediana
Assimetria à direita (positiva)
Média < Mediana
Assimetria à esquerda (negativa)
A mediana é robusta: não é afetada por valores extremos, sendo a medida preferível em distribuições assimétricas.
5.2.3 Moda
A moda é o valor mais frequente. É a única medida de tendência central aplicável a dados qualitativos nominais.
Uma distribuição pode ser unimodal (uma moda), bimodal (duas modas) ou multimodal (mais de duas). A presença de bimodalidade frequentemente indica a existência de subgrupos distintos nos dados.
O denominador é \((n-1)\) e não \(n\) pela correção de Bessel: ao calcular a variância amostral usando a média amostral (que já foi estimada a partir dos mesmos dados), perde-se um grau de liberdade. O uso de \((n-1)\) torna o estimador não viesado da variância populacional.
A principal vantagem sobre a variância é que o desvio padrão tem a mesma unidade dos dados originais, facilitando a interpretação.
Regra empírica para distribuições normais:
68% dos dados estão dentro de \(\bar{x} \pm s\)
95% dos dados estão dentro de \(\bar{x} \pm 2s\)
99,7% dos dados estão dentro de \(\bar{x} \pm 3s\)
5.3.3 Coeficiente de variação
O coeficiente de variação (CV) é uma medida de dispersão relativa, expressa em percentual:
\[CV = \frac{s}{\bar{x}} \times 100\%\]
Permite comparar a variabilidade entre variáveis com unidades diferentes ou médias muito discrepantes.
Interpretação para dados biológicos:
CV
Classificação
< 10%
Baixa dispersão
10% - 20%
Dispersão moderada
20% - 30%
Dispersão alta
> 30%
Dispersão muito alta
Atenção
O CV não é adequado quando a média está próxima de zero ou quando os dados incluem valores negativos. Nesses casos, o CV pode produzir valores sem sentido ou negativos.
Valores fora do intervalo \([LI, LS]\) são classificados como outliers moderados. Valores além de \(Q1 - 3 \times IQR\) ou \(Q3 + 3 \times IQR\) são outliers extremos.
Atenção
Nunca remova outliers automaticamente apenas para “melhorar” os resultados. Investigue a origem de cada valor discrepante. Outliers podem ser erros de medição (corrigir ou remover com justificativa) ou observações biologicamente reais e importantes (manter). Documente sempre a decisão.
Q1 <-quantile(CO2$uptake, 0.25)Q3 <-quantile(CO2$uptake, 0.75)iqr <-IQR(CO2$uptake)LI <- Q1 -1.5* iqrLS <- Q3 +1.5* iqroutliers <- CO2$uptake[CO2$uptake < LI | CO2$uptake > LS]data.frame(Medida =c("Q1", "Mediana", "Q3", "IQR", "Limite inferior", "Limite superior", "N de outliers"),Valor =round(c(Q1, median(CO2$uptake), Q3, iqr, LI, LS, length(outliers)), 3)) |>kable(caption ="Medidas de posição e critério de outliers")
Medidas de posição e critério de outliers
Medida
Valor
Q1
17.900
Mediana
28.300
Q3
37.125
IQR
19.225
Limite inferior
-10.938
Limite superior
65.963
N de outliers
0.000
5.5 Estatísticas descritivas completas
# Usando psych::describe para estatísticas detalhadaspsych::describe(CO2$uptake) |>kable(caption ="Estatísticas descritivas completas - absorção de CO₂", digits =3)
Estatísticas descritivas completas - absorção de CO₂
vars
n
mean
sd
median
trimmed
mad
min
max
range
skew
kurtosis
se
X1
1
84
27.213
10.814
28.3
27.326
14.826
7.7
45.5
37.8
-0.104
-1.348
1.18
5.6 Estatísticas por grupo
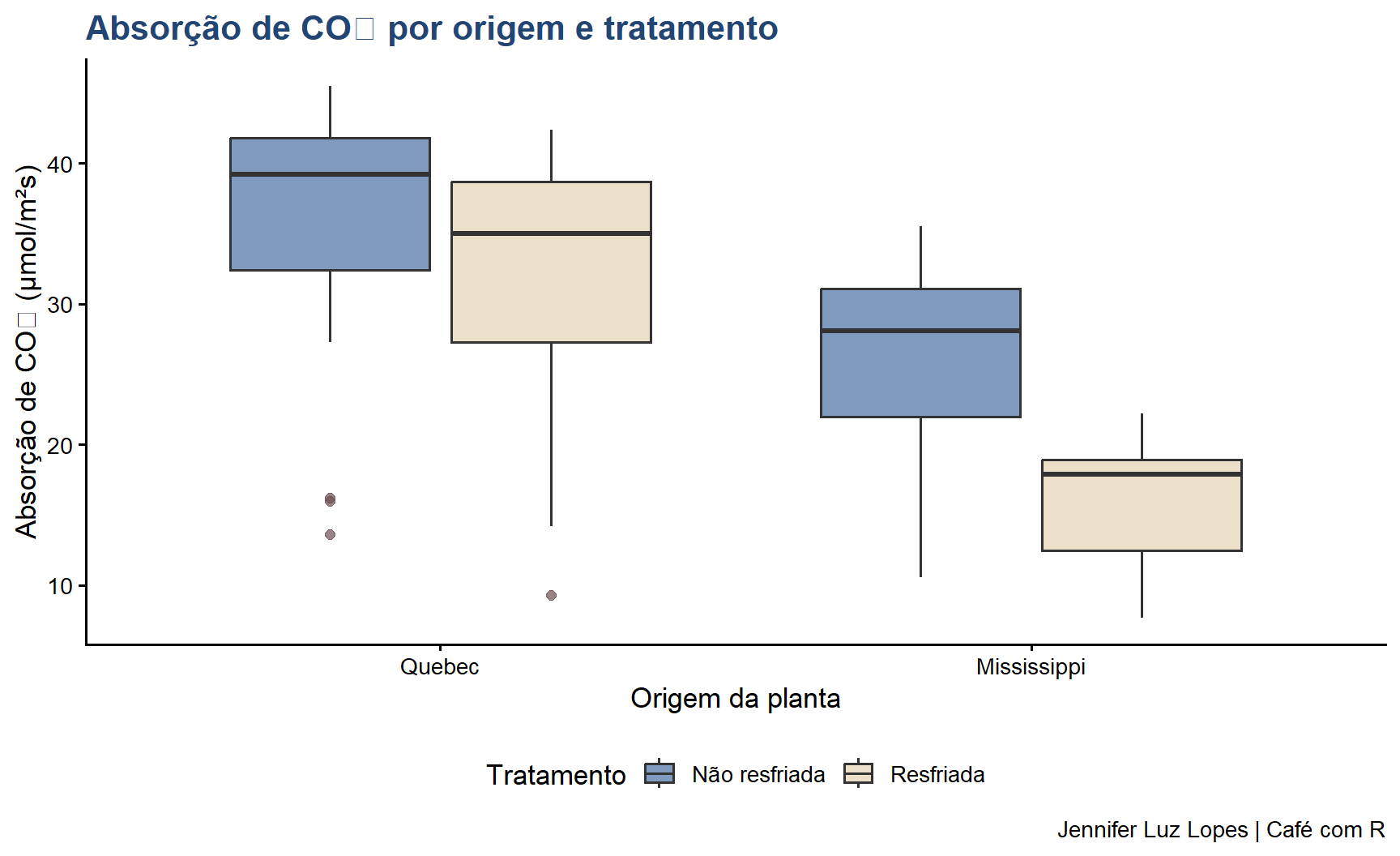
estatisticas_grupos <- CO2 |>group_by(Type, Treatment) |>summarise(n =n(),Media =round(mean(uptake), 2),Mediana =round(median(uptake), 2),DP =round(sd(uptake), 2),CV =round(sd(uptake) /mean(uptake) *100, 1),Min =min(uptake),Max =max(uptake),IQR =round(IQR(uptake), 2),.groups ="drop")kable(estatisticas_grupos, caption ="Estatísticas descritivas por grupo experimental")
Estatísticas descritivas por grupo experimental
Type
Treatment
n
Media
Mediana
DP
CV
Min
Max
IQR
Quebec
nonchilled
21
35.33
39.2
9.60
27.2
13.6
45.5
9.4
Quebec
chilled
21
31.75
35.0
9.64
30.4
9.3
42.4
11.4
Mississippi
nonchilled
21
25.95
28.1
7.40
28.5
10.6
35.5
9.1
Mississippi
chilled
21
15.81
17.9
4.06
25.7
7.7
22.2
6.4
5.7 Visualizações
5.7.1 Histograma com densidade
media <-mean(CO2$uptake)mediana <-median(CO2$uptake)ggplot(CO2, aes(x = uptake)) +geom_histogram(aes(y =after_stat(density)),bins =15,fill ="#4A6FA5",color ="#224573",alpha =0.7) +geom_density(color ="#6B4F4F", linewidth =1.5) +geom_vline(xintercept = media,color ="#224573",linetype ="dashed",linewidth =1) +geom_vline(xintercept = mediana,color ="#6B4F4F",linetype ="dotted",linewidth =1) +annotate("text", x = media +1.5, y =0.032,label =paste("Média:", round(media, 1)),color ="#224573", hjust =0, size =3.8) +annotate("text", x = mediana -1.5, y =0.028,label =paste("Mediana:", round(mediana, 1)),color ="#6B4F4F", hjust =1, size =3.8) +labs(title ="Distribuição da absorção de CO₂",subtitle ="Linha tracejada: média | Linha pontilhada: mediana",x ="Absorção de CO₂ (μmol/m²s)",y ="Densidade", caption ="Jennifer Luz Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"),plot.subtitle =element_text(color ="#6B4F4F"))
5.7.2 Boxplot por grupos
ggplot(CO2, aes(x = Type, y = uptake, fill = Treatment)) +geom_boxplot(alpha =0.7,outlier.color ="#6B4F4F",outlier.size =2) +scale_fill_manual(values =c("#4A6FA5", "#E5D3B3"),labels =c("Não resfriada", "Resfriada")) +labs(title ="Absorção de CO₂ por origem e tratamento",x ="Origem da planta",y ="Absorção de CO₂ (μmol/m²s)",fill ="Tratamento",caption ="Jennifer Luz Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"),legend.position ="bottom")
5.7.3 Violin plot
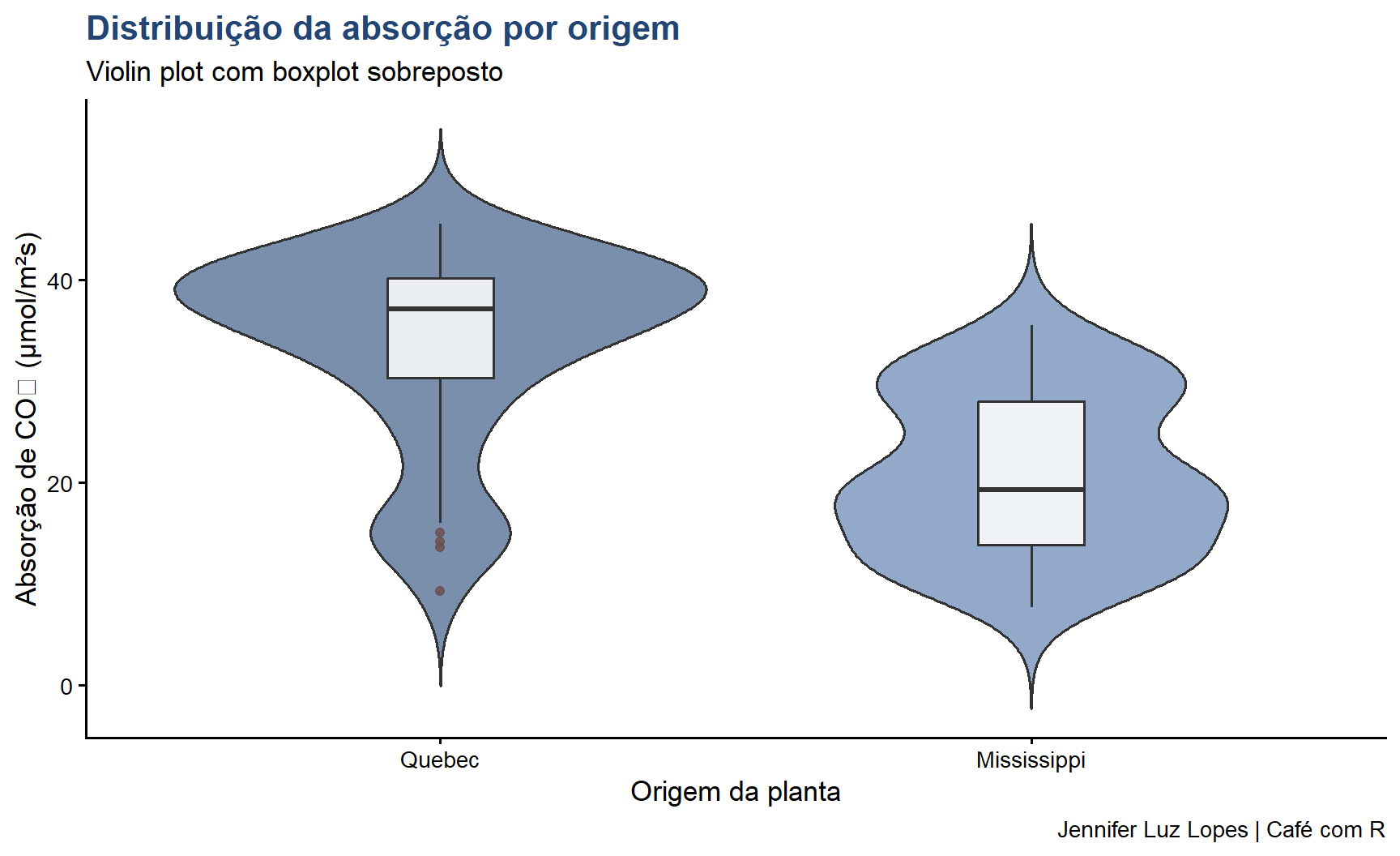
ggplot(CO2, aes(x = Type, y = uptake, fill = Type)) +geom_violin(alpha =0.6, trim =FALSE) +geom_boxplot(width =0.18,fill ="white",alpha =0.85,outlier.color ="#6B4F4F") +scale_fill_manual(values =c("#224573", "#4A6FA5")) +labs(title ="Distribuição da absorção por origem",subtitle ="Violin plot com boxplot sobreposto",x ="Origem da planta",y ="Absorção de CO₂ (μmol/m²s)",caption ="Jennifer Luz Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"),legend.position ="none")
Boas práticas
Prefira violin plots a boxplots simples quando o tamanho amostral for suficiente (n > 20 por grupo). O violin plot revela a forma completa da distribuição, incluindo multimodalidade, que o boxplot oculta.
Código fonte
---title: "Estatística descritiva"---```{r setup, include=FALSE}knitr::opts_chunk$set(echo=TRUE, warning=FALSE, message=FALSE, fig.align="center", fig.width=9, fig.height=5.5)library(tidyverse); library(psych); library(knitr); library(kableExtra)cores_cafe <-c("#224573", "#6B4F4F", "#4A6FA5", "#E5D3B3")data("CO2")```## FundamentosA **estatística descritiva** organiza, resume e apresenta dados de forma informativa, sem fazer inferências além do que foi observado. É o ponto de partida obrigatório de qualquer análise: conhecer os dados antes de modelá-los.Seus principais componentes são:- **Medidas de tendência central**: onde os dados se concentram- **Medidas de dispersão**: o quanto os dados se afastam do centro- **Medidas de posição**: localização relativa dentro da distribuição- **Medidas de forma**: assimetria e achatamento da distribuição## Medidas de tendência central### Média aritméticaA média aritmética é a soma de todos os valores dividida pelo número de observações:$$\bar{x} = \frac{1}{n}\sum_{i=1}^{n}x_i$$**Propriedades:**- Sensível a valores extremos - um único outlier pode distorcê-la significativamente- Única para cada conjunto de dados- Minimiza a soma dos quadrados dos desvios**Quando usar:** dados quantitativos contínuos com distribuição aproximadamente simétrica e sem outliers extremos.### MedianaA mediana é o valor central do conjunto ordenado de dados. Metade das observações fica abaixo e metade acima.**Comparação média - mediana:**| Relação | Interpretação ||------------------|----------------------------------------|| Média ≈ Mediana | Distribuição aproximadamente simétrica || Média \> Mediana | Assimetria à direita (positiva) || Média \< Mediana | Assimetria à esquerda (negativa) |A mediana é **robusta**: não é afetada por valores extremos, sendo a medida preferível em distribuições assimétricas.### ModaA moda é o valor mais frequente. É a única medida de tendência central aplicável a dados qualitativos nominais.Uma distribuição pode ser **unimodal** (uma moda), **bimodal** (duas modas) ou **multimodal** (mais de duas). A presença de bimodalidade frequentemente indica a existência de subgrupos distintos nos dados.### Cálculo em R```{r tendencia_central}media_uptake <-mean(CO2$uptake)mediana_uptake <-median(CO2$uptake)cat("Média: ", round(media_uptake, 2), "\n")cat("Mediana:", round(mediana_uptake, 2), "\n")# Resumo completosummary(CO2$uptake)```## Medidas de dispersãoDois conjuntos de dados com a mesma média podem ser completamente diferentes na variabilidade. As medidas de dispersão capturam essa diferença.### VariânciaA variância amostral é a média dos quadrados dos desvios em relação à média:$$s^2 = \frac{1}{n-1}\sum_{i=1}^{n}(x_i - \bar{x})^2$$O denominador é $(n-1)$ e não $n$ pela **correção de Bessel**: ao calcular a variância amostral usando a média amostral (que já foi estimada a partir dos mesmos dados), perde-se um grau de liberdade. O uso de $(n-1)$ torna o estimador não viesado da variância populacional.### Desvio padrãoO desvio padrão é a raiz quadrada da variância:$$s = \sqrt{\frac{1}{n-1}\sum_{i=1}^{n}(x_i - \bar{x})^2}$$A principal vantagem sobre a variância é que o desvio padrão tem **a mesma unidade dos dados originais**, facilitando a interpretação.**Regra empírica para distribuições normais:**- 68% dos dados estão dentro de $\bar{x} \pm s$- 95% dos dados estão dentro de $\bar{x} \pm 2s$- 99,7% dos dados estão dentro de $\bar{x} \pm 3s$### Coeficiente de variaçãoO coeficiente de variação (CV) é uma medida de dispersão **relativa**, expressa em percentual:$$CV = \frac{s}{\bar{x}} \times 100\%$$Permite comparar a variabilidade entre variáveis com unidades diferentes ou médias muito discrepantes.**Interpretação para dados biológicos:**| CV | Classificação ||-----------|----------------------||\< 10% | Baixa dispersão || 10% - 20% | Dispersão moderada || 20% - 30% | Dispersão alta ||\> 30% | Dispersão muito alta |::: callout-warning## AtençãoO CV não é adequado quando a média está próxima de zero ou quando os dados incluem valores negativos. Nesses casos, o CV pode produzir valores sem sentido ou negativos.:::### Cálculo em R```{r dispersao}var_uptake <-var(CO2$uptake)dp_uptake <-sd(CO2$uptake)amp_uptake <-diff(range(CO2$uptake))cv_uptake <- (dp_uptake / media_uptake) *100data.frame(Medida =c("Variância", "Desvio padrão", "Amplitude", "CV (%)"),Valor =round(c(var_uptake, dp_uptake, amp_uptake, cv_uptake), 3)) |>kable(caption ="Medidas de dispersão - absorção de CO₂")```## Medidas de posição### Quartis e percentisOs **quartis** dividem o conjunto ordenado em quatro partes iguais:- **Q1**: 25% dos dados estão abaixo deste valor- **Q2**: mediana (50%)- **Q3**: 75% dos dados estão abaixo deste valorOs **percentis** dividem os dados em 100 partes iguais. Q1 = P25, Q2 = P50, Q3 = P75.### Amplitude interquartílica (IQR)$$IQR = Q3 - Q1$$O IQR representa os 50% centrais dos dados e é **robusto a outliers**, sendo preferível ao desvio padrão em distribuições assimétricas.### Identificação de outliers pelo critério IQRO critério proposto por Tukey define:$$LI = Q1 - 1.5 \times IQR \quad \text{e} \quad LS = Q3 + 1.5 \times IQR$$Valores fora do intervalo $[LI, LS]$ são classificados como outliers moderados. Valores além de $Q1 - 3 \times IQR$ ou $Q3 + 3 \times IQR$ são outliers extremos.::: callout-warning## AtençãoNunca remova outliers automaticamente apenas para "melhorar" os resultados. Investigue a origem de cada valor discrepante. Outliers podem ser erros de medição (corrigir ou remover com justificativa) ou observações biologicamente reais e importantes (manter). Documente sempre a decisão.:::```{r quartis_outliers}Q1 <-quantile(CO2$uptake, 0.25)Q3 <-quantile(CO2$uptake, 0.75)iqr <-IQR(CO2$uptake)LI <- Q1 -1.5* iqrLS <- Q3 +1.5* iqroutliers <- CO2$uptake[CO2$uptake < LI | CO2$uptake > LS]data.frame(Medida =c("Q1", "Mediana", "Q3", "IQR", "Limite inferior", "Limite superior", "N de outliers"),Valor =round(c(Q1, median(CO2$uptake), Q3, iqr, LI, LS, length(outliers)), 3)) |>kable(caption ="Medidas de posição e critério de outliers")```## Estatísticas descritivas completas```{r descritivas_completas}# Usando psych::describe para estatísticas detalhadaspsych::describe(CO2$uptake) |>kable(caption ="Estatísticas descritivas completas - absorção de CO₂", digits =3)```## Estatísticas por grupo```{r por_grupo}estatisticas_grupos <- CO2 |>group_by(Type, Treatment) |>summarise(n =n(),Media =round(mean(uptake), 2),Mediana =round(median(uptake), 2),DP =round(sd(uptake), 2),CV =round(sd(uptake) /mean(uptake) *100, 1),Min =min(uptake),Max =max(uptake),IQR =round(IQR(uptake), 2),.groups ="drop")kable(estatisticas_grupos, caption ="Estatísticas descritivas por grupo experimental")```## Visualizações### Histograma com densidade```{r histograma}media <-mean(CO2$uptake)mediana <-median(CO2$uptake)ggplot(CO2, aes(x = uptake)) +geom_histogram(aes(y =after_stat(density)),bins =15,fill ="#4A6FA5",color ="#224573",alpha =0.7) +geom_density(color ="#6B4F4F", linewidth =1.5) +geom_vline(xintercept = media,color ="#224573",linetype ="dashed",linewidth =1) +geom_vline(xintercept = mediana,color ="#6B4F4F",linetype ="dotted",linewidth =1) +annotate("text", x = media +1.5, y =0.032,label =paste("Média:", round(media, 1)),color ="#224573", hjust =0, size =3.8) +annotate("text", x = mediana -1.5, y =0.028,label =paste("Mediana:", round(mediana, 1)),color ="#6B4F4F", hjust =1, size =3.8) +labs(title ="Distribuição da absorção de CO₂",subtitle ="Linha tracejada: média | Linha pontilhada: mediana",x ="Absorção de CO₂ (μmol/m²s)",y ="Densidade", caption ="Jennifer Luz Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"),plot.subtitle =element_text(color ="#6B4F4F"))```### Boxplot por grupos```{r boxplot}ggplot(CO2, aes(x = Type, y = uptake, fill = Treatment)) +geom_boxplot(alpha =0.7,outlier.color ="#6B4F4F",outlier.size =2) +scale_fill_manual(values =c("#4A6FA5", "#E5D3B3"),labels =c("Não resfriada", "Resfriada")) +labs(title ="Absorção de CO₂ por origem e tratamento",x ="Origem da planta",y ="Absorção de CO₂ (μmol/m²s)",fill ="Tratamento",caption ="Jennifer Luz Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"),legend.position ="bottom")```### Violin plot```{r violin}ggplot(CO2, aes(x = Type, y = uptake, fill = Type)) +geom_violin(alpha =0.6, trim =FALSE) +geom_boxplot(width =0.18,fill ="white",alpha =0.85,outlier.color ="#6B4F4F") +scale_fill_manual(values =c("#224573", "#4A6FA5")) +labs(title ="Distribuição da absorção por origem",subtitle ="Violin plot com boxplot sobreposto",x ="Origem da planta",y ="Absorção de CO₂ (μmol/m²s)",caption ="Jennifer Luz Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"),legend.position ="none")```::: callout-tip## Boas práticasPrefira violin plots a boxplots simples quando o tamanho amostral for suficiente (n \> 20 por grupo). O violin plot revela a forma completa da distribuição, incluindo multimodalidade, que o boxplot oculta.:::