ANOVA (Analysis of Variance) é uma técnica desenvolvida por Ronald Fisher para comparar médias de três ou mais grupos simultaneamente, testando se existe diferença significativa entre eles.
O nome pode parecer contraditório: o objetivo é comparar médias, mas a técnica analisa variâncias. A lógica é: se os grupos têm médias diferentes, a variabilidade entre grupos será maior do que a variabilidade dentro dos grupos.
9.1.1 Por que não fazer múltiplos testes t?
Para comparar 4 grupos, seriam necessárias \(\binom{4}{2} = 6\) comparações. Com α = 0,05 por teste:
\[P(\text{pelo menos um falso positivo}) = 1 - (0{,}95)^6 \approx 0{,}265\]
A probabilidade de cometer pelo menos um erro tipo I salta para 26,5%. A ANOVA controla o erro tipo I globalmente, mantendo-o em 5%.
9.2 Decomposição da variância
A variância total dos dados é decomposta em duas partes:
\[SS_{total} = SS_{entre} + SS_{dentro}\]
\(SS_{entre}\): soma dos quadrados entre grupos (variabilidade explicada pelo fator)
\(SS_{dentro}\): soma dos quadrados dentro dos grupos (variabilidade residual)
A estatística F é a razão entre os quadrados médios correspondentes:
Onde \(k\) é o número de grupos e \(N\) o total de observações. Sob H₀ (sem diferença entre grupos), \(F \approx 1\).
9.3 Pressupostos da ANOVA
Pressuposto
Como verificar
Solução se violado
Independência
Delineamento experimental
Garantir na coleta
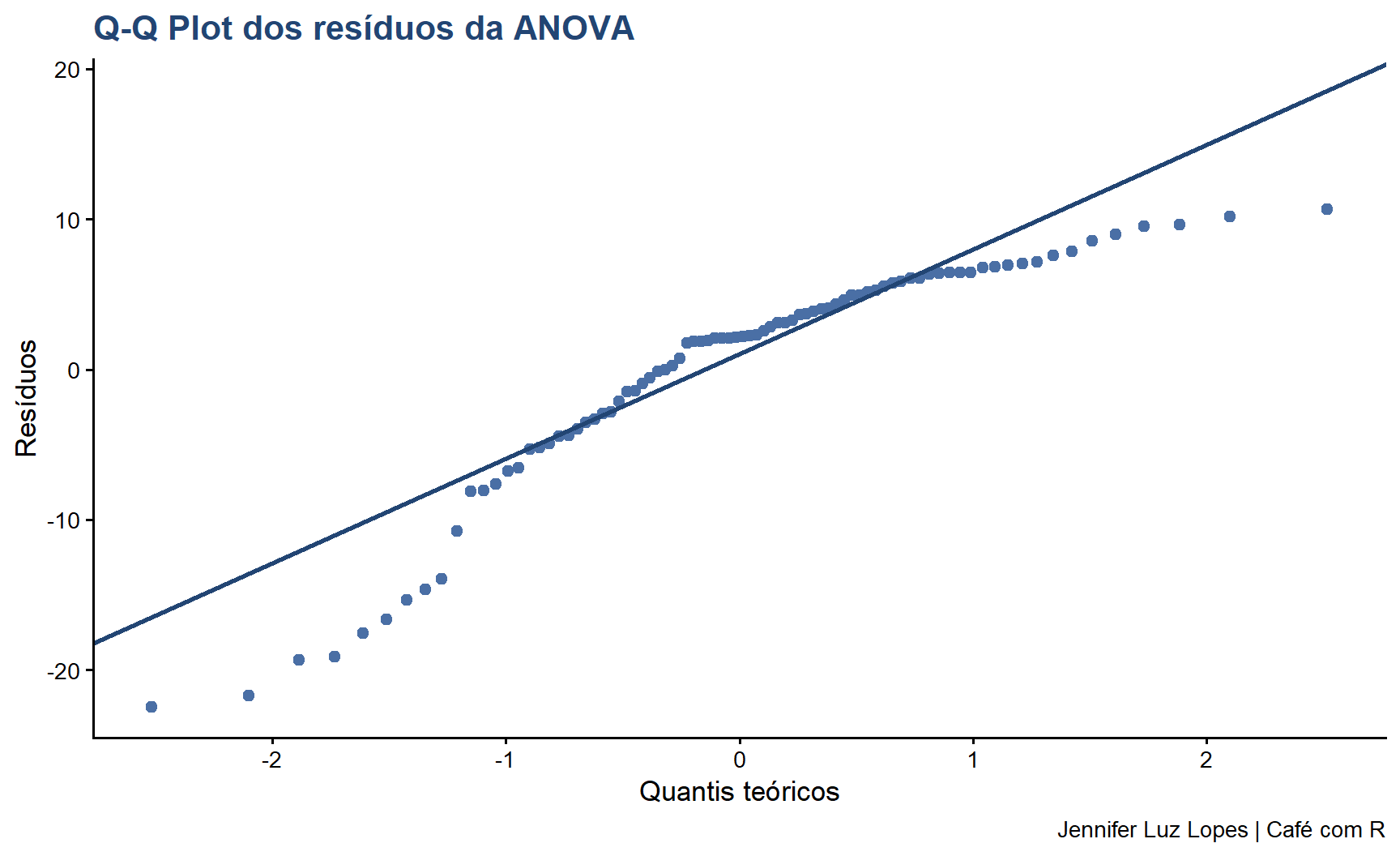
Normalidade dos resíduos
Shapiro-Wilk, Q-Q plot
Log, raiz, Kruskal-Wallis
Homocedasticidade
Teste de Levene
ANOVA de Welch, transformação
Atenção
A independência das observações é o pressuposto mais crítico e o único que não pode ser corrigido estatisticamente. Deve ser garantido pelo delineamento experimental. Violações de normalidade e homocedasticidade têm soluções disponíveis; violação de independência invalida a análise.
9.4 ANOVA one-way: efeito da origem
Pergunta: existe diferença significativa na absorção de CO₂ entre plantas de Quebec e Mississippi?
anova_tipo <-aov(uptake ~ Type, data = CO2)summary(anova_tipo)
Df Sum Sq Mean Sq F value Pr(>F)
Type 1 3366 3366 43.52 3.83e-09 ***
Residuals 82 6341 77
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
as.data.frame(summary(anova_tipo)[[1]]) |>kable(digits =4, caption ="ANOVA one-way - efeito da origem da planta")
ANOVA one-way - efeito da origem da planta
Df
Sum Sq
Mean Sq
F value
Pr(>F)
Type
1
3365.534
3365.5344
43.5191
0
Residuals
82
6341.441
77.3346
NA
NA
Interpretação: o valor F elevado e o p-valor < 0,001 levam à rejeição de H₀. Há diferença significativa na absorção entre as duas origens.
9.5 ANOVA two-way: origem e tratamento
Pergunta: como a origem e o tratamento afetam a absorção? Existe interação entre os dois fatores?
anova_completa <-aov(uptake ~ Type * Treatment, data = CO2)summary(anova_completa)
Df Sum Sq Mean Sq F value Pr(>F)
Type 1 3366 3366 52.509 2.38e-10 ***
Treatment 1 988 988 15.416 0.000182 ***
Type:Treatment 1 226 226 3.522 0.064213 .
Residuals 80 5128 64
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
as.data.frame(summary(anova_completa)[[1]]) |>kable(digits =4, caption ="ANOVA two-way - efeitos principais e interação")
ANOVA two-way - efeitos principais e interação
Df
Sum Sq
Mean Sq
F value
Pr(>F)
Type
1
3365.5344
3365.5344
52.5086
0.0000
Treatment
1
988.1144
988.1144
15.4164
0.0002
Type:Treatment
1
225.7296
225.7296
3.5218
0.0642
Residuals
80
5127.5971
64.0950
NA
NA
9.5.1 Interpretação dos efeitos
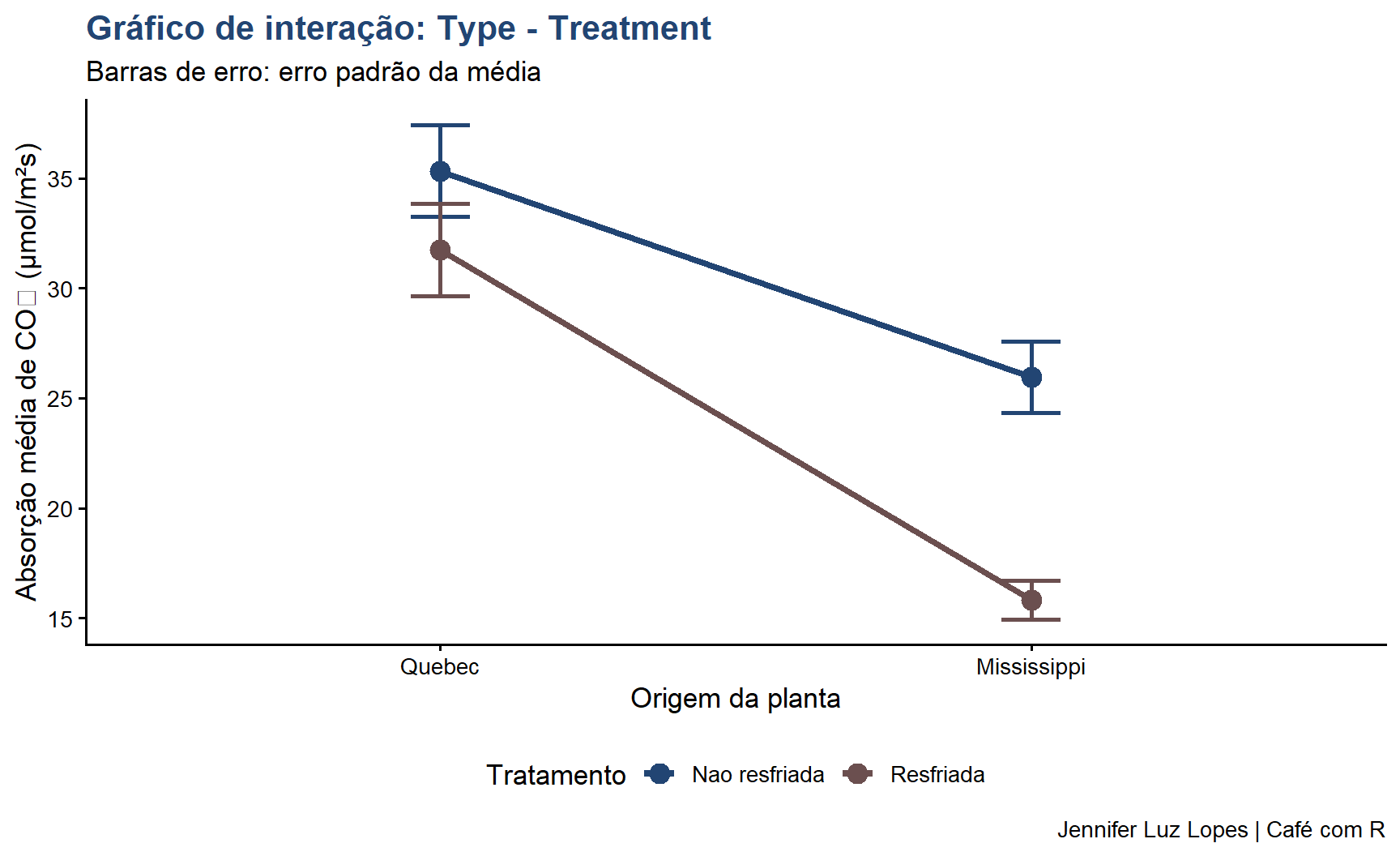
Efeito principal de Type: significativo (p < 0,001) - plantas de Quebec e Mississippi absorvem quantidades diferentes de CO₂
Efeito principal de Treatment: significativo (p < 0,001) - o resfriamento reduz a absorção
Interação Type × Treatment: marginalmente não significativa (p ≈ 0,073) - o efeito do resfriamento tende a ser diferente entre as origens, mas não atinge o nível de 5%
medias_grupo <- CO2 |>group_by(Type, Treatment) |>summarise(Media =mean(uptake),EP =sd(uptake) /sqrt(n()),.groups ="drop")ggplot(medias_grupo,aes(x = Type, y = Media, color = Treatment, group = Treatment)) +geom_line(linewidth =1.5) +geom_point(size =4) +geom_errorbar(aes(ymin = Media - EP, ymax = Media + EP),width =0.1, linewidth =1) +scale_color_manual(values =c("#224573", "#6B4F4F"),labels =c("Nao resfriada", "Resfriada")) +labs(title ="Gráfico de interação: Type - Treatment",subtitle ="Barras de erro: erro padrão da média",x ="Origem da planta",y ="Absorção média de CO₂ (μmol/m²s)",color ="Tratamento", caption ="Jennifer Luz Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"),legend.position ="bottom")
Conceito
Linhas paralelas no gráfico de interação indicam ausência de interação: o efeito de um fator é o mesmo em todos os níveis do outro fator. Linhas que se cruzam ou divergem indicam interação: o efeito de um fator depende do nível do outro.
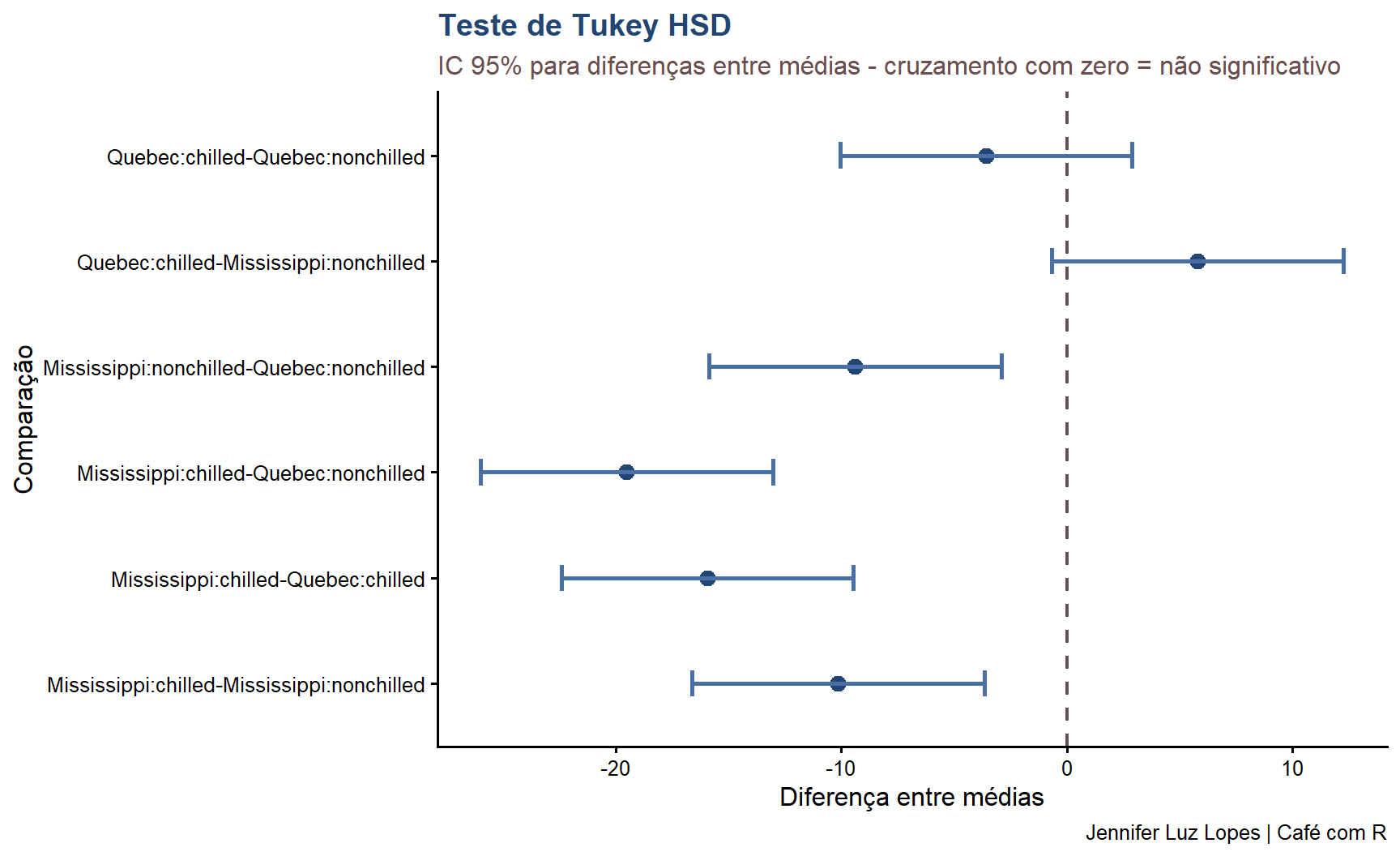
9.8 Testes post-hoc: Tukey HSD
Após ANOVA significativa, o teste post-hoc identifica quais pares de grupos diferem entre si, controlando o erro tipo I para comparações múltiplas.
ggplot(tukey_df, aes(x = Comparacao, y = diff)) +geom_point(size =3, color ="#224573") +geom_errorbar(aes(ymin = lwr, ymax = upr),width =0.25,color ="#4A6FA5",linewidth =1) +geom_hline(yintercept =0,linetype ="dashed",color ="#6B4F4F",linewidth =0.8) +coord_flip() +labs(title ="Teste de Tukey HSD",subtitle ="IC 95% para diferenças entre médias - cruzamento com zero = não significativo",x ="Comparação",y ="Diferença entre médias",caption ="Jennifer Luz Lopes | Café com R") +theme_classic(base_size =12) +theme(plot.title =element_text(color ="#224573", face ="bold"),plot.subtitle =element_text(color ="#6B4F4F"))
9.9 ANOVA com medidas repetidas: modelo misto
Cada planta foi medida nas 7 concentrações, violando o pressuposto de independência da ANOVA tradicional. O modelo misto trata a planta como efeito aleatório, acomodando a correlação entre observações da mesma planta.
library(nlme)modelo_misto <- nlme::lme( uptake ~ Type * Treatment * conc,random =~1| Plant,data = CO2)anova(modelo_misto) |>kable(digits =4, caption ="ANOVA do modelo misto - efeito aleatório por planta")
ANOVA do modelo misto - efeito aleatório por planta
numDF
denDF
F-value
p-value
(Intercept)
1
68
1759.5333
0.0000
Type
1
8
95.1955
0.0000
Treatment
1
8
27.9492
0.0007
conc
1
68
68.6194
0.0000
Type:Treatment
1
8
6.3849
0.0354
Type:conc
1
68
6.2463
0.0149
Treatment:conc
1
68
0.9571
0.3314
Type:Treatment:conc
1
68
1.6677
0.2009
Boas práticas
Quando as mesmas unidades experimentais são medidas em múltiplas condições (medidas repetidas), use sempre um modelo que reconheça essa estrutura (modelo misto, ANOVA de medidas repetidas). Ignorar a dependência entre observações produz erros padrão subestimados e p-valores inflados.
Código fonte
---title: "ANOVA: análise de variância"---```{r setup, include=FALSE}knitr::opts_chunk$set(echo=TRUE, warning=FALSE, message=FALSE, fig.align="center", fig.width=9, fig.height=5.5)library(tidyverse); library(car); library(DescTools); library(effectsize); library(knitr)cores_cafe <-c("#224573", "#6B4F4F", "#4A6FA5", "#E5D3B3")data("CO2")```## O que é ANOVA**ANOVA (Analysis of Variance)** é uma técnica desenvolvida por Ronald Fisher para comparar médias de três ou mais grupos simultaneamente, testando se existe diferença significativa entre eles.O nome pode parecer contraditório: o objetivo é comparar médias, mas a técnica analisa variâncias. A lógica é: se os grupos têm médias diferentes, a **variabilidade entre grupos** será maior do que a **variabilidade dentro dos grupos**.### Por que não fazer múltiplos testes t?Para comparar 4 grupos, seriam necessárias $\binom{4}{2} = 6$ comparações. Com α = 0,05 por teste:$$P(\text{pelo menos um falso positivo}) = 1 - (0{,}95)^6 \approx 0{,}265$$A probabilidade de cometer pelo menos um erro tipo I salta para 26,5%. A ANOVA controla o erro tipo I globalmente, mantendo-o em 5%.## Decomposição da variânciaA variância total dos dados é decomposta em duas partes:$$SS_{total} = SS_{entre} + SS_{dentro}$$- $SS_{entre}$: soma dos quadrados entre grupos (variabilidade explicada pelo fator)- $SS_{dentro}$: soma dos quadrados dentro dos grupos (variabilidade residual)A **estatística F** é a razão entre os quadrados médios correspondentes:$$F = \frac{MS_{entre}}{MS_{dentro}} = \frac{SS_{entre}/(k-1)}{SS_{dentro}/(N-k)}$$Onde $k$ é o número de grupos e $N$ o total de observações. Sob H₀ (sem diferença entre grupos), $F \approx 1$.## Pressupostos da ANOVA| Pressuposto | Como verificar | Solução se violado ||------------------------|------------------------|------------------------|| Independência | Delineamento experimental | Garantir na coleta || Normalidade dos resíduos | Shapiro-Wilk, Q-Q plot | Log, raiz, Kruskal-Wallis || Homocedasticidade | Teste de Levene | ANOVA de Welch, transformação |::: callout-warning## AtençãoA independência das observações é o pressuposto mais crítico e o único que não pode ser corrigido estatisticamente. Deve ser garantido pelo delineamento experimental. Violações de normalidade e homocedasticidade têm soluções disponíveis; violação de independência invalida a análise.:::## ANOVA one-way: efeito da origem**Pergunta:** existe diferença significativa na absorção de CO₂ entre plantas de Quebec e Mississippi?```{r anova_oneway}anova_tipo <-aov(uptake ~ Type, data = CO2)summary(anova_tipo)``````{r anova_oneway_tabela}as.data.frame(summary(anova_tipo)[[1]]) |>kable(digits =4, caption ="ANOVA one-way - efeito da origem da planta")```**Interpretação:** o valor F elevado e o p-valor \< 0,001 levam à rejeição de H₀. Há diferença significativa na absorção entre as duas origens.## ANOVA two-way: origem e tratamento**Pergunta:** como a origem e o tratamento afetam a absorção? Existe interação entre os dois fatores?```{r anova_twoway}anova_completa <-aov(uptake ~ Type * Treatment, data = CO2)summary(anova_completa)``````{r anova_twoway_tabela}as.data.frame(summary(anova_completa)[[1]]) |>kable(digits =4, caption ="ANOVA two-way - efeitos principais e interação")```### Interpretação dos efeitos1. **Efeito principal de Type**: significativo (p \< 0,001) - plantas de Quebec e Mississippi absorvem quantidades diferentes de CO₂2. **Efeito principal de Treatment**: significativo (p \< 0,001) - o resfriamento reduz a absorção3. **Interação Type × Treatment**: marginalmente não significativa (p ≈ 0,073) - o efeito do resfriamento tende a ser diferente entre as origens, mas não atinge o nível de 5%## Verificação de pressupostos### Normalidade dos resíduos```{r normalidade_residuos}residuos <-residuals(anova_completa)shapiro_res <-shapiro.test(residuos)cat("Shapiro-Wilk nos resíduos - W:", round(shapiro_res$statistic, 4),"| p-valor:", round(shapiro_res$p.value, 4), "\n")ggplot(data.frame(residuos), aes(sample = residuos)) +stat_qq(color ="#4A6FA5", size =2) +stat_qq_line(color ="#224573", linewidth =1) +labs(title ="Q-Q Plot dos resíduos da ANOVA",x ="Quantis teóricos",y ="Resíduos", caption ="Jennifer Luz Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"))```### Homocedasticidade (Levene)```{r levene}levene_resultado <- car::leveneTest(uptake ~ Type * Treatment, data = CO2)cat("Teste de Levene - F:", round(levene_resultado$`F value`[1], 4),"| p-valor:", round(levene_resultado$`Pr(>F)`[1], 4), "\n")if (levene_resultado$`Pr(>F)`[1] >0.05) {cat("Conclusao: variâncias homogêneas (pressuposto atendido)\n")} else {cat("Conclusão: variâncias heterogêneas - usar ANOVA de Welch ou transformar dados\n")}```## Gráfico de interação```{r interacao}medias_grupo <- CO2 |>group_by(Type, Treatment) |>summarise(Media =mean(uptake),EP =sd(uptake) /sqrt(n()),.groups ="drop")ggplot(medias_grupo,aes(x = Type, y = Media, color = Treatment, group = Treatment)) +geom_line(linewidth =1.5) +geom_point(size =4) +geom_errorbar(aes(ymin = Media - EP, ymax = Media + EP),width =0.1, linewidth =1) +scale_color_manual(values =c("#224573", "#6B4F4F"),labels =c("Nao resfriada", "Resfriada")) +labs(title ="Gráfico de interação: Type - Treatment",subtitle ="Barras de erro: erro padrão da média",x ="Origem da planta",y ="Absorção média de CO₂ (μmol/m²s)",color ="Tratamento", caption ="Jennifer Luz Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"),legend.position ="bottom")```::: callout-note## ConceitoLinhas paralelas no gráfico de interação indicam ausência de interação: o efeito de um fator é o mesmo em todos os níveis do outro fator. Linhas que se cruzam ou divergem indicam interação: o efeito de um fator **depende** do nível do outro.:::## Testes post-hoc: Tukey HSDApós ANOVA significativa, o teste post-hoc identifica quais pares de grupos diferem entre si, controlando o erro tipo I para comparações múltiplas.```{r tukey}tukey_resultado <-TukeyHSD(anova_completa)# Extraindo a interaçãotukey_df <-as.data.frame(tukey_resultado$`Type:Treatment`)tukey_df$Comparacao <-rownames(tukey_df)kable(tukey_df |>select(Comparacao, diff, lwr, upr, `p adj`),digits =4,caption ="Tukey HSD - comparações múltiplas (Type:Treatment)")``````{r tukey_plot}ggplot(tukey_df, aes(x = Comparacao, y = diff)) +geom_point(size =3, color ="#224573") +geom_errorbar(aes(ymin = lwr, ymax = upr),width =0.25,color ="#4A6FA5",linewidth =1) +geom_hline(yintercept =0,linetype ="dashed",color ="#6B4F4F",linewidth =0.8) +coord_flip() +labs(title ="Teste de Tukey HSD",subtitle ="IC 95% para diferenças entre médias - cruzamento com zero = não significativo",x ="Comparação",y ="Diferença entre médias",caption ="Jennifer Luz Lopes | Café com R") +theme_classic(base_size =12) +theme(plot.title =element_text(color ="#224573", face ="bold"),plot.subtitle =element_text(color ="#6B4F4F"))```## ANOVA com medidas repetidas: modelo mistoCada planta foi medida nas 7 concentrações, violando o pressuposto de independência da ANOVA tradicional. O modelo misto trata a planta como **efeito aleatório**, acomodando a correlação entre observações da mesma planta.```{r modelo_misto}library(nlme)modelo_misto <- nlme::lme( uptake ~ Type * Treatment * conc,random =~1| Plant,data = CO2)anova(modelo_misto) |>kable(digits =4, caption ="ANOVA do modelo misto - efeito aleatório por planta")```::: callout-tip## Boas práticasQuando as mesmas unidades experimentais são medidas em múltiplas condições (medidas repetidas), use sempre um modelo que reconheça essa estrutura (modelo misto, ANOVA de medidas repetidas). Ignorar a dependência entre observações produz erros padrão subestimados e p-valores inflados.:::