A regressão linear simples modela a relação linear entre uma variável preditora (\(X\)) e uma variável resposta (\(Y\)):
\[Y = \beta_0 + \beta_1 X + \varepsilon\]
\(\beta_0\): intercepto (valor esperado de \(Y\) quando \(X = 0\))
\(\beta_1\): coeficiente angular (variação esperada em \(Y\) para cada unidade de incremento em \(X\))
\(\varepsilon\): erro aleatório, assumido com distribuição normal, média zero e variância constante
Os coeficientes \(\beta\) são estimados pelo método dos mínimos quadrados ordinários (MQO): minimizar a soma dos quadrados dos resíduos \(\sum(Y_i - \hat{Y}_i)^2\).
10.2 Pressupostos da regressão linear
Pressuposto
Descrição
Como verificar
Linearidade
Relação linear entre X e Y
Gráfico resíduos vs ajustados
Independência
Resíduos independentes entre si
Delineamento experimental
Homocedasticidade
Variância dos resíduos constante
Gráfico resíduos vs ajustados
Normalidade
Resíduos com distribuição normal
Q-Q plot, Shapiro-Wilk
Ausência de outliers influentes
Sem pontos com alta influência
Cook’s distance, leverage
10.3 Modelo linear simples
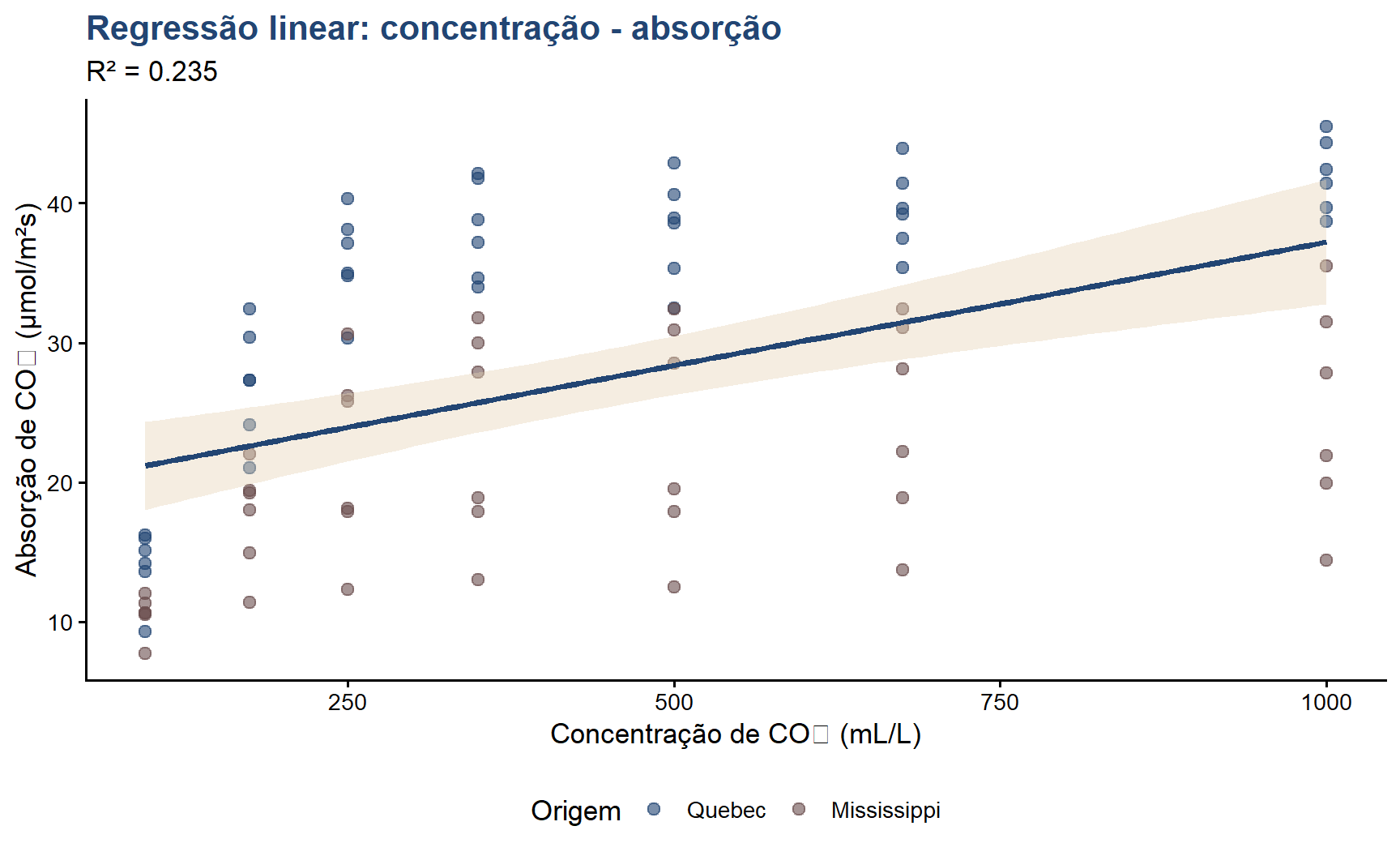
Pergunta: a concentração de CO₂ prediz linearmente a taxa de absorção?
modelo_linear <-lm(uptake ~ conc, data = CO2)summary(modelo_linear)
Call:
lm(formula = uptake ~ conc, data = CO2)
Residuals:
Min 1Q Median 3Q Max
-22.831 -7.729 1.483 7.748 16.394
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 19.500290 1.853080 10.523 < 2e-16 ***
conc 0.017731 0.003529 5.024 2.91e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 9.514 on 82 degrees of freedom
Multiple R-squared: 0.2354, Adjusted R-squared: 0.2261
F-statistic: 25.25 on 1 and 82 DF, p-value: 2.906e-06
tidy(modelo_linear) |>kable(digits =4, caption ="Coeficientes do modelo linear")
Coeficientes do modelo linear
term
estimate
std.error
statistic
p.value
(Intercept)
19.5003
1.8531
10.5232
0
conc
0.0177
0.0035
5.0245
0
glance(modelo_linear) |>select(r.squared, adj.r.squared, sigma, statistic, p.value, df, nobs) |>kable(digits =4, caption ="Métricas de ajuste do modelo")
Métricas de ajuste do modelo
r.squared
adj.r.squared
sigma
statistic
p.value
df
nobs
0.2354
0.2261
9.5138
25.2452
0
1
84
Interpretação:
Para cada aumento de 1 mL/L na concentração, a absorção aumenta em média 0,016 μmol/m²s
O modelo explica aproximadamente 37% da variabilidade em uptake (R² = 0,37)
O intercepto (absorção quando conc = 0) não tem interpretação biológica direta
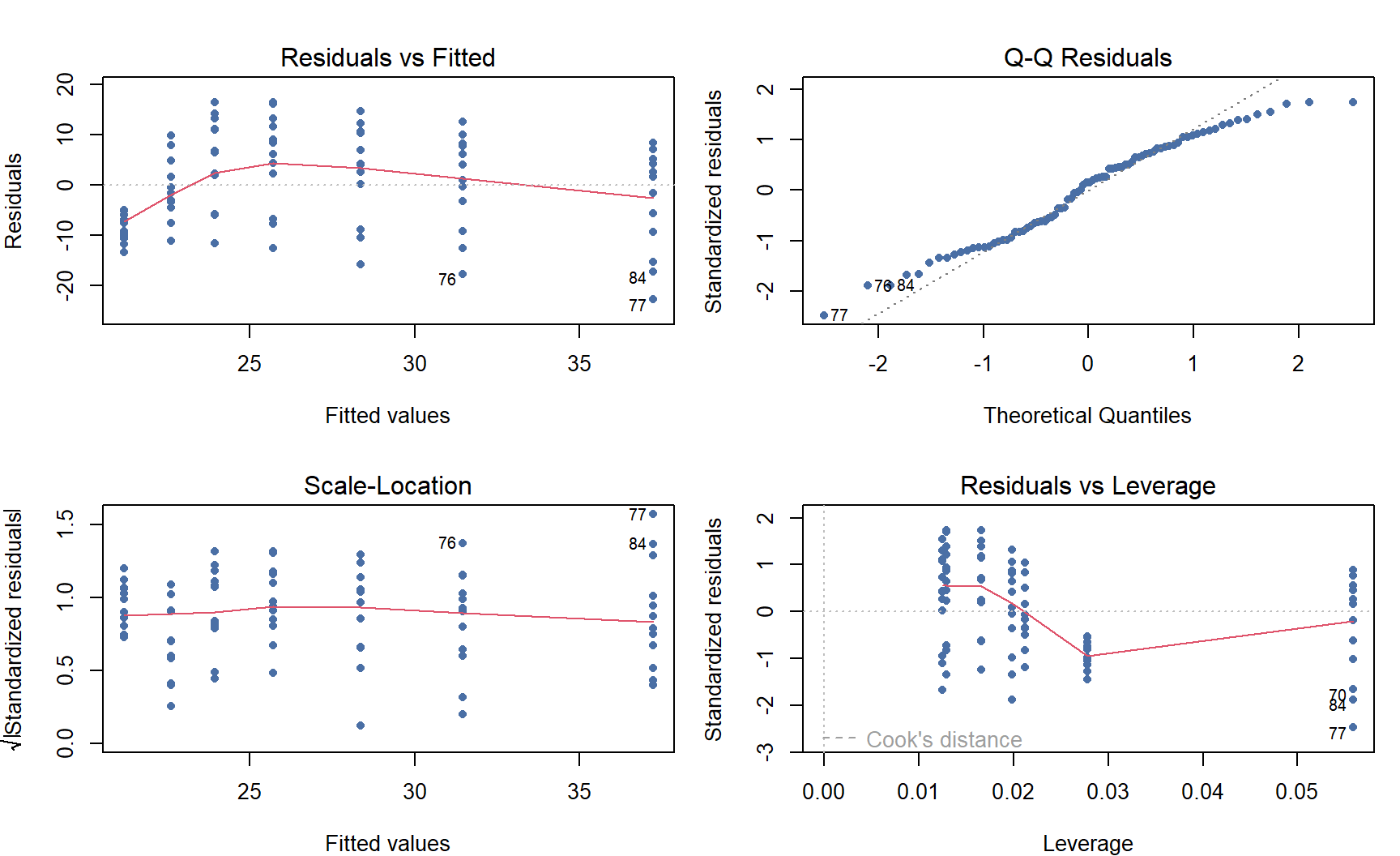
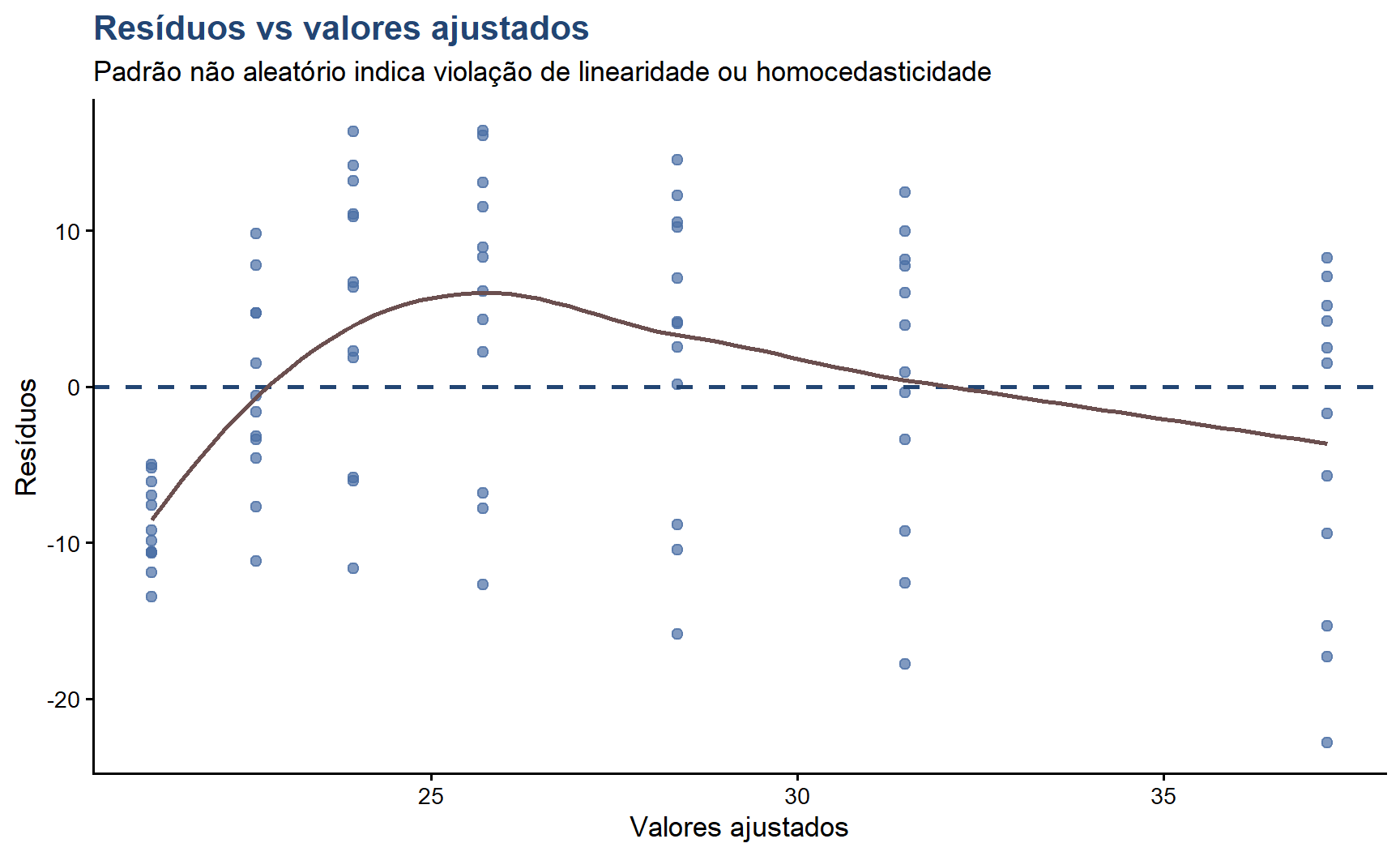
Residuals vs Fitted (resíduos vs valores ajustados): Deve mostrar pontos aleatoriamente distribuídos em torno de zero, sem padrão. Padrão em U ou funil indica não-linearidade ou heterocedasticidade.
Normal Q-Q: Pontos alinhados à diagonal indicam normalidade dos resíduos. Desvios nas extremidades são comuns e geralmente toleráveis.
Scale-Location (raiz dos resíduos padronizados vs ajustados): Linha horizontal indica homocedasticidade. Linha crescente indica heterocedasticidade (variância aumenta com os valores ajustados).
Residuals vs Leverage: Identifica pontos influentes. Pontos além da distância de Cook de 0,5 ou 1 merecem atenção especial.
10.6 Diagnóstico detalhado: um painel por vez
diag_df <-augment(modelo_linear)# Resíduos vs ajustadosggplot(diag_df, aes(x = .fitted, y = .resid)) +geom_point(color ="#4A6FA5", size =2, alpha =0.7) +geom_hline(yintercept =0,color ="#224573",linetype ="dashed",linewidth =1) +geom_smooth(se =FALSE, color ="#6B4F4F", linewidth =1) +labs(title ="Resíduos vs valores ajustados",subtitle ="Padrão não aleatório indica violação de linearidade ou homocedasticidade",x ="Valores ajustados",y ="Resíduos",capition ="Jennifer Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"))
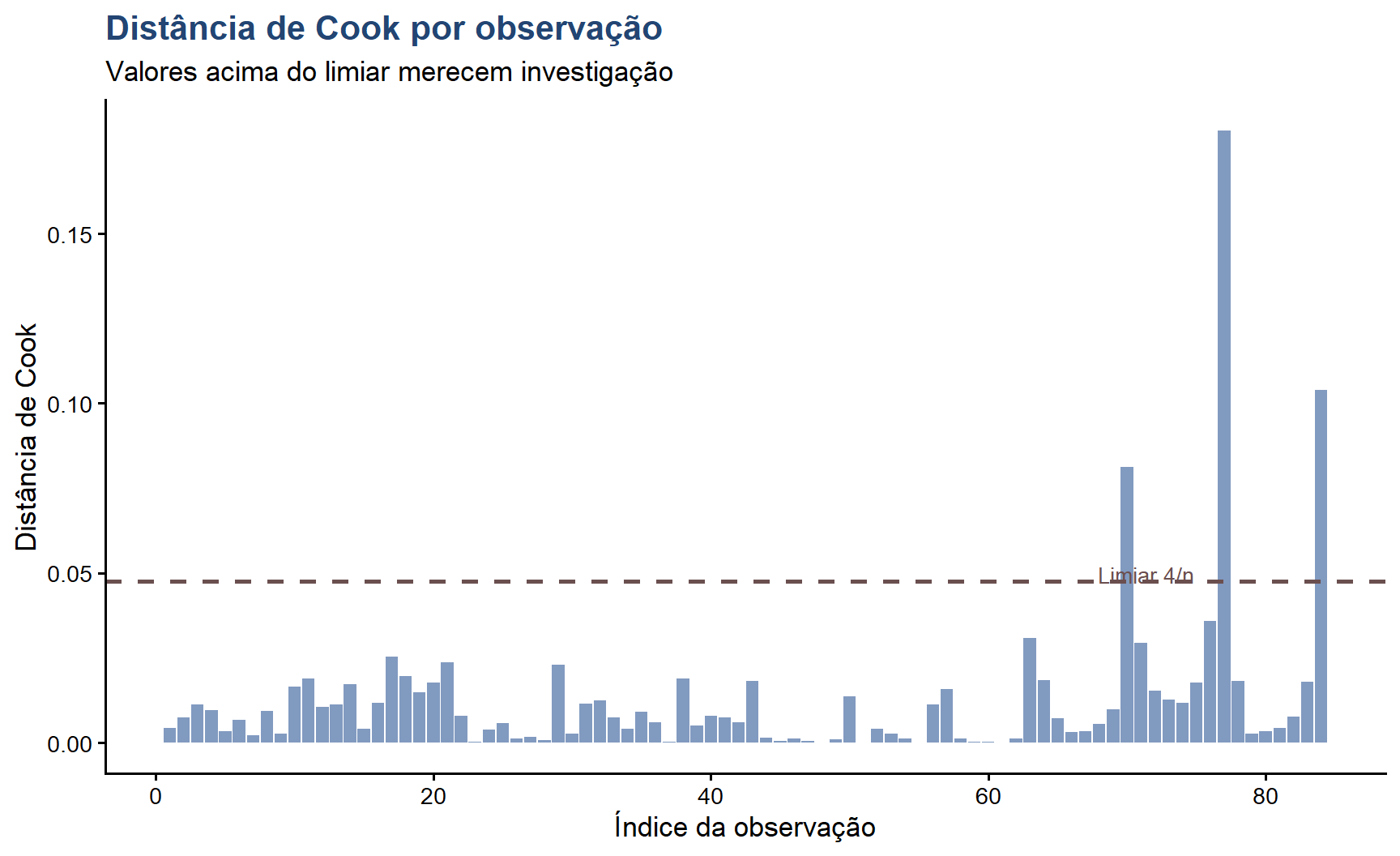
# Distância de Cook - identificar pontos influentesggplot(diag_df, aes(x =seq_len(nrow(diag_df)), y = .cooksd)) +geom_bar(stat ="identity",fill ="#4A6FA5",alpha =0.7) +geom_hline(yintercept =4/nrow(diag_df),color ="#6B4F4F",linetype ="dashed",linewidth =1) +annotate("text",x =nrow(diag_df) *0.85,y =4/nrow(diag_df) +0.002,label ="Limiar 4/n",color ="#6B4F4F",size =3.5) +labs(title ="Distância de Cook por observação",subtitle ="Valores acima do limiar merecem investigação",x ="Índice da observação",y ="Distância de Cook",capition ="Jennifer Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"))
Conceito
A distância de Cook mede a influência de cada observação no ajuste do modelo como um todo. Um ponto influente altera significativamente os coeficientes quando removido. O limiar comum é 4/n, mas valores acima de 1 são considerados mais críticos.
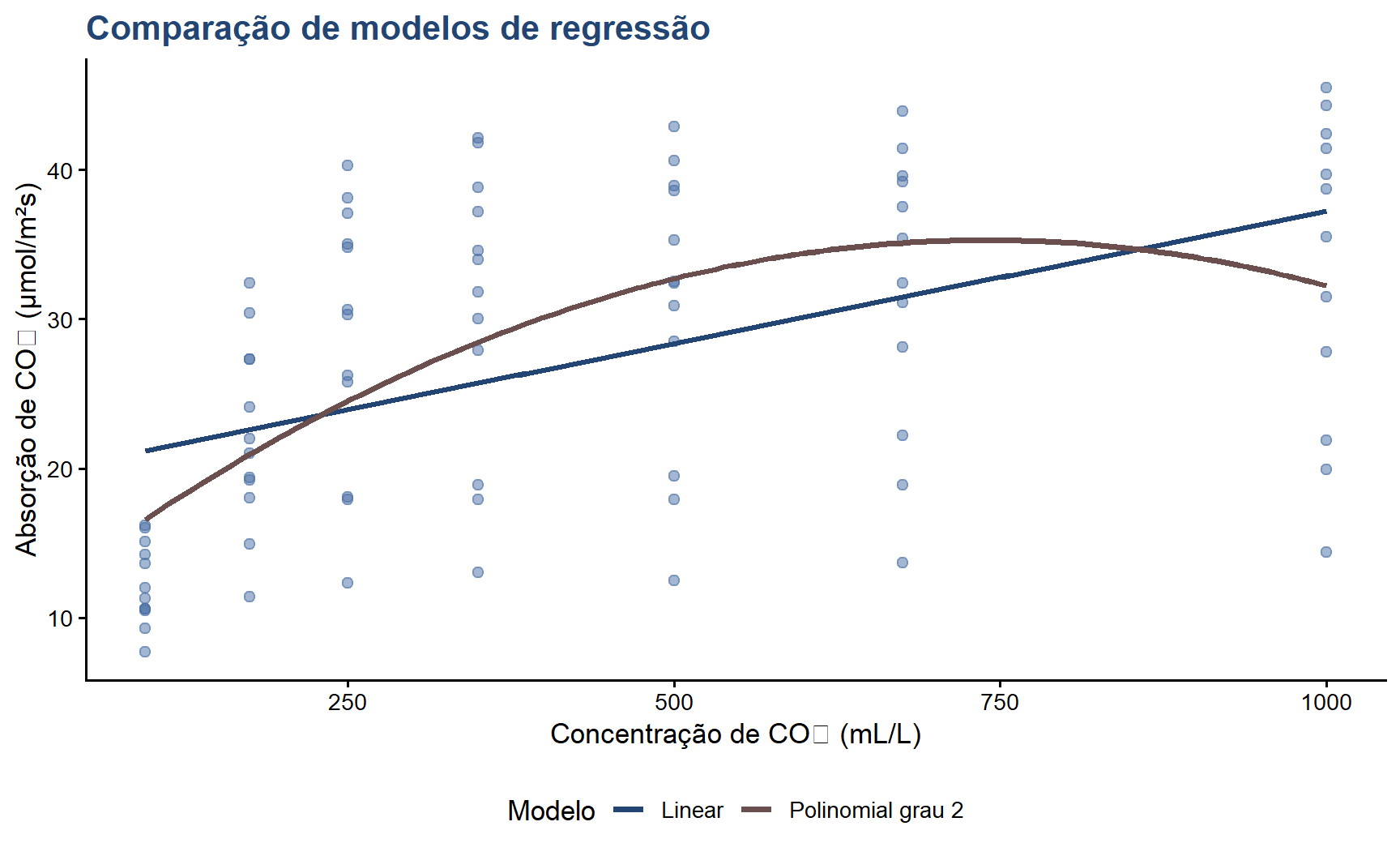
A relação entre concentração e absorção sugere saturação: o crescimento desacelera em concentrações mais altas, indicando uma curva e não uma reta.
modelo_poly <-lm(uptake ~poly(conc, 2), data = CO2)summary(modelo_poly)
Call:
lm(formula = uptake ~ poly(conc, 2), data = CO2)
Residuals:
Min 1Q Median 3Q Max
-21.4051 -5.9844 -0.0679 6.3711 15.8080
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 27.2131 0.9664 28.160 < 2e-16 ***
poly(conc, 2)1 47.8016 8.8569 5.397 6.58e-07 ***
poly(conc, 2)2 -32.6790 8.8569 -3.690 0.000405 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 8.857 on 81 degrees of freedom
Multiple R-squared: 0.3454, Adjusted R-squared: 0.3292
F-statistic: 21.37 on 2 and 81 DF, p-value: 3.521e-08
# Comparação formal via ANOVAanova(modelo_linear, modelo_poly) |>kable(digits =4, caption ="Comparação: modelo linear vs polinomial")
Comparação: modelo linear vs polinomial
Res.Df
RSS
Df
Sum of Sq
F
Pr(>F)
82
7421.982
NA
NA
NA
NA
81
6354.067
1
1067.915
13.6135
4e-04
pred_df <-data.frame(conc =seq(min(CO2$conc), max(CO2$conc), length.out =150))pred_df$pred_linear <-predict(modelo_linear, pred_df)pred_df$pred_poly <-predict(modelo_poly, pred_df)ggplot(CO2, aes(x = conc, y = uptake)) +geom_point(color ="#4A6FA5", size =2, alpha =0.5) +geom_line(data = pred_df,aes(y = pred_linear, color ="Linear"),linewidth =1.3) +geom_line(data = pred_df,aes(y = pred_poly, color ="Polinomial grau 2"),linewidth =1.3) +scale_color_manual(values =c("Linear"="#224573","Polinomial grau 2"="#6B4F4F")) +labs(title ="Comparação de modelos de regressão",x ="Concentração de CO₂ (mL/L)",y ="Absorção de CO₂ (μmol/m²s)",color ="Modelo",capition ="Jennifer Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"),legend.position ="bottom")
Boas práticas
Prefira o modelo mais simples que descreve bem os dados (princípio da parcimônia). Use o AIC, BIC e o teste F (via anova()) para comparar modelos com diferentes complexidades. Um R² maior não justifica automaticamente um modelo mais complexo.
Código fonte
---title: "Regressão linear e diagnóstico"---```{r setup, include=FALSE}knitr::opts_chunk$set(echo=TRUE, warning=FALSE, message=FALSE, fig.align="center", fig.width=9, fig.height=5.5)library(tidyverse); library(car); library(broom); library(knitr)cores_cafe <-c("#224573", "#6B4F4F", "#4A6FA5", "#E5D3B3")data("CO2")```## Fundamentos da regressão linearA **regressão linear simples** modela a relação linear entre uma variável preditora ($X$) e uma variável resposta ($Y$):$$Y = \beta_0 + \beta_1 X + \varepsilon$$- $\beta_0$: intercepto (valor esperado de $Y$ quando $X = 0$)- $\beta_1$: coeficiente angular (variação esperada em $Y$ para cada unidade de incremento em $X$)- $\varepsilon$: erro aleatório, assumido com distribuição normal, média zero e variância constanteOs coeficientes $\beta$ são estimados pelo método dos **mínimos quadrados ordinários (MQO)**: minimizar a soma dos quadrados dos resíduos $\sum(Y_i - \hat{Y}_i)^2$.## Pressupostos da regressão linear| Pressuposto | Descrição | Como verificar ||------------------------|------------------------|------------------------|| Linearidade | Relação linear entre X e Y | Gráfico resíduos vs ajustados || Independência | Resíduos independentes entre si | Delineamento experimental || Homocedasticidade | Variância dos resíduos constante | Gráfico resíduos vs ajustados || Normalidade | Resíduos com distribuição normal | Q-Q plot, Shapiro-Wilk || Ausência de outliers influentes | Sem pontos com alta influência | Cook's distance, leverage |## Modelo linear simples**Pergunta:** a concentração de CO₂ prediz linearmente a taxa de absorção?```{r modelo_linear}modelo_linear <-lm(uptake ~ conc, data = CO2)summary(modelo_linear)``````{r coeficientes}tidy(modelo_linear) |>kable(digits =4, caption ="Coeficientes do modelo linear")``````{r metricas}glance(modelo_linear) |>select(r.squared, adj.r.squared, sigma, statistic, p.value, df, nobs) |>kable(digits =4, caption ="Métricas de ajuste do modelo")```**Interpretação:**- Para cada aumento de 1 mL/L na concentração, a absorção aumenta em média 0,016 μmol/m²s- O modelo explica aproximadamente 37% da variabilidade em `uptake` (R² = 0,37)- O intercepto (absorção quando conc = 0) não tem interpretação biológica direta## Visualização do modelo```{r viz_regressao}ggplot(CO2, aes(x = conc, y = uptake)) +geom_point(aes(color = Type), size =2.5, alpha =0.6) +geom_smooth(method ="lm",color ="#224573",fill ="#E5D3B3",linewidth =1.3,se =TRUE) +scale_color_manual(values =c("#224573", "#6B4F4F")) +labs(title ="Regressão linear: concentração - absorção",subtitle =paste0("R² = ", round(summary(modelo_linear)$r.squared, 3)),x ="Concentração de CO₂ (mL/L)",y ="Absorção de CO₂ (μmol/m²s)",color ="Origem",capition ="Jennifer Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"),legend.position ="bottom")```## Diagnóstico completo do modeloO diagnóstico de resíduos é obrigatório após qualquer ajuste de regressão. Os quatro gráficos a seguir cobrem os principais pressupostos.```{r diagnostico_4panels}par(mfrow =c(2, 2), mar =c(4, 4, 3, 1))plot(modelo_linear,col ="#4A6FA5",pch =16,cex =0.8)par(mfrow =c(1, 1))```### Leitura dos gráficos de diagnóstico**Residuals vs Fitted (resíduos vs valores ajustados):** Deve mostrar pontos aleatoriamente distribuídos em torno de zero, sem padrão. Padrão em U ou funil indica não-linearidade ou heterocedasticidade.**Normal Q-Q:** Pontos alinhados à diagonal indicam normalidade dos resíduos. Desvios nas extremidades são comuns e geralmente toleráveis.**Scale-Location (raiz dos resíduos padronizados vs ajustados):** Linha horizontal indica homocedasticidade. Linha crescente indica heterocedasticidade (variância aumenta com os valores ajustados).**Residuals vs Leverage:** Identifica pontos influentes. Pontos além da distância de Cook de 0,5 ou 1 merecem atenção especial.## Diagnóstico detalhado: um painel por vez```{r residuos_ajustados}diag_df <-augment(modelo_linear)# Resíduos vs ajustadosggplot(diag_df, aes(x = .fitted, y = .resid)) +geom_point(color ="#4A6FA5", size =2, alpha =0.7) +geom_hline(yintercept =0,color ="#224573",linetype ="dashed",linewidth =1) +geom_smooth(se =FALSE, color ="#6B4F4F", linewidth =1) +labs(title ="Resíduos vs valores ajustados",subtitle ="Padrão não aleatório indica violação de linearidade ou homocedasticidade",x ="Valores ajustados",y ="Resíduos",capition ="Jennifer Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"))``````{r cook}# Distância de Cook - identificar pontos influentesggplot(diag_df, aes(x =seq_len(nrow(diag_df)), y = .cooksd)) +geom_bar(stat ="identity",fill ="#4A6FA5",alpha =0.7) +geom_hline(yintercept =4/nrow(diag_df),color ="#6B4F4F",linetype ="dashed",linewidth =1) +annotate("text",x =nrow(diag_df) *0.85,y =4/nrow(diag_df) +0.002,label ="Limiar 4/n",color ="#6B4F4F",size =3.5) +labs(title ="Distância de Cook por observação",subtitle ="Valores acima do limiar merecem investigação",x ="Índice da observação",y ="Distância de Cook",capition ="Jennifer Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"))```::: callout-note## ConceitoA **distância de Cook** mede a influência de cada observação no ajuste do modelo como um todo. Um ponto influente altera significativamente os coeficientes quando removido. O limiar comum é 4/n, mas valores acima de 1 são considerados mais críticos.:::## Testes formais dos pressupostos```{r testes_pressupostos}residuos_lm <-residuals(modelo_linear)# Normalidade dos resíduossw <-shapiro.test(residuos_lm)cat("Shapiro-Wilk - W:", round(sw$statistic, 4),"| p-valor:", round(sw$p.value, 4), "\n")# Homocedasticidade (Breusch-Pagan via car::ncvTest)ncv <- car::ncvTest(modelo_linear)cat("Breusch-Pagan (ncvTest) - Qui²:", round(ncv$ChiSquare, 4),"| p-valor:", round(ncv$p, 4), "\n")```## Modelo múltiplo: concentração, origem e tratamento```{r modelo_multiplo}modelo_multiplo <-lm(uptake ~ conc + Type + Treatment, data = CO2)summary(modelo_multiplo)``````{r coef_multiplo}tidy(modelo_multiplo) |>kable(digits =4, caption ="Coeficientes do modelo múltiplo")``````{r metricas_multiplo}# Comparando modelosbind_rows(glance(modelo_linear) |>mutate(Modelo ="Linear simples"),glance(modelo_multiplo) |>mutate(Modelo ="Múltiplo")) |>select(Modelo, r.squared, adj.r.squared, AIC, BIC) |>kable(digits =4, caption ="Comparação de modelos")```## Modelo polinomialA relação entre concentração e absorção sugere saturação: o crescimento desacelera em concentrações mais altas, indicando uma curva e não uma reta.```{r modelo_polinomial}modelo_poly <-lm(uptake ~poly(conc, 2), data = CO2)summary(modelo_poly)# Comparação formal via ANOVAanova(modelo_linear, modelo_poly) |>kable(digits =4, caption ="Comparação: modelo linear vs polinomial")``````{r viz_modelos}pred_df <-data.frame(conc =seq(min(CO2$conc), max(CO2$conc), length.out =150))pred_df$pred_linear <-predict(modelo_linear, pred_df)pred_df$pred_poly <-predict(modelo_poly, pred_df)ggplot(CO2, aes(x = conc, y = uptake)) +geom_point(color ="#4A6FA5", size =2, alpha =0.5) +geom_line(data = pred_df,aes(y = pred_linear, color ="Linear"),linewidth =1.3) +geom_line(data = pred_df,aes(y = pred_poly, color ="Polinomial grau 2"),linewidth =1.3) +scale_color_manual(values =c("Linear"="#224573","Polinomial grau 2"="#6B4F4F")) +labs(title ="Comparação de modelos de regressão",x ="Concentração de CO₂ (mL/L)",y ="Absorção de CO₂ (μmol/m²s)",color ="Modelo",capition ="Jennifer Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"),legend.position ="bottom")```::: callout-tip## Boas práticasPrefira o modelo mais simples que descreve bem os dados (princípio da parcimônia). Use o AIC, BIC e o teste F (via `anova()`) para comparar modelos com diferentes complexidades. Um R² maior não justifica automaticamente um modelo mais complexo.:::