Probabilidade é uma medida numérica da chance de ocorrência de um evento, variando de 0 (impossível) a 1 (certeza). Uma distribuição de probabilidade descreve como as probabilidades se distribuem entre os possíveis valores de uma variável aleatória.
Para variáveis contínuas, usamos a função densidade de probabilidade (PDF). Para variáveis discretas, usamos a função massa de probabilidade (PMF).
6.2 A distribuição normal
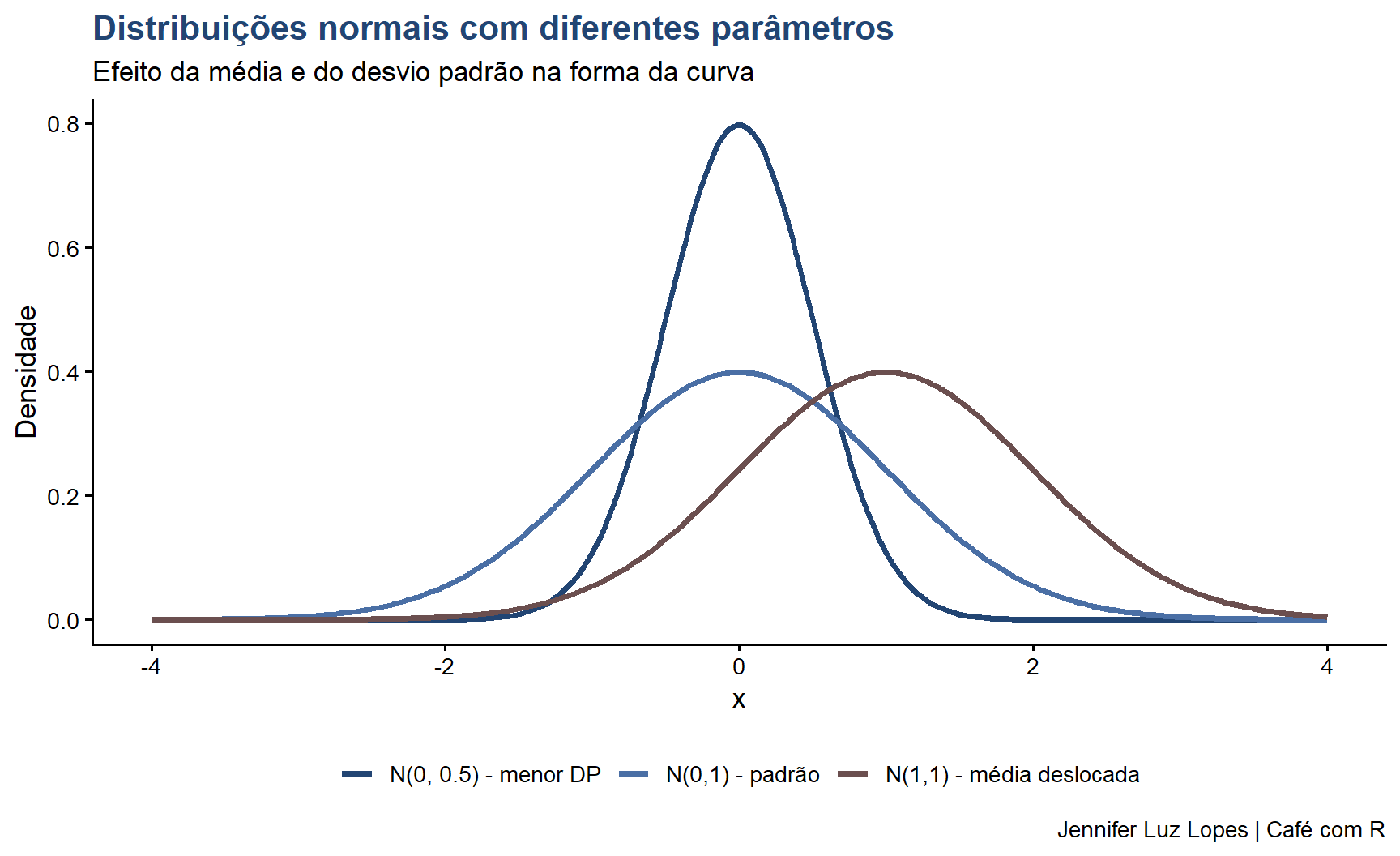
A distribuição normal (gaussiana) é a distribuição de probabilidade mais importante em estatística. Caracterizada por dois parâmetros, \(\mu\) (média) e \(\sigma\) (desvio padrão), sua função densidade é:
Simétrica em torno de \(\mu\): média = mediana = moda
Forma de sino: decresce suavemente em ambas as direções
Área total = 1: a probabilidade total de todos os eventos é 1
Assintótica: as caudas se aproximam do eixo horizontal sem tocá-lo
6.2.2 Regra empírica (68-95-99,7)
Para qualquer distribuição normal:
Intervalo
Proporção dos dados
\(\bar{x} \pm 1s\)
≈ 68%
\(\bar{x} \pm 1{,}96s\)
≈ 95%
\(\bar{x} \pm 3s\)
≈ 99,7%
6.2.3 Por que a distribuição normal importa?
Ocorrência natural: altura, peso, erros de medição, rendimentos agrícolas tendem a ser normalmente distribuídos
Teorema Central do Limite (TCL): a distribuição das médias amostrais converge para a normal conforme \(n\) aumenta, independentemente da distribuição original
Fundamento dos testes paramétricos: teste t, ANOVA e regressão linear assumem normalidade dos resíduos
Conceito
O TCL justifica o uso de testes paramétricos mesmo quando os dados individuais não são perfeitamente normais, desde que o tamanho amostral seja adequado (geralmente n ≥ 30 por grupo).
6.2.4 Padronização - Z-score
Qualquer variável normal pode ser convertida para a escala padrão (μ = 0, σ = 1):
\[Z = \frac{X - \mu}{\sigma}\]
O Z-score indica quantos desvios padrão um valor está acima (Z > 0) ou abaixo (Z < 0) da média. Valores com |Z| > 3 são extremamente raros em distribuições normais.
# Demonstração: distribuição normal com diferentes parâmetrosx <-seq(-4, 4, length.out =300)df_normal <-data.frame(x =rep(x, 3),y =c(dnorm(x, 0, 1),dnorm(x, 0, 0.5),dnorm(x, 1, 1)),Curva =rep(c("N(0,1) - padrão","N(0, 0.5) - menor DP","N(1,1) - média deslocada"),each =300))ggplot(df_normal, aes(x = x, y = y, color = Curva)) +geom_line(linewidth =1.4) +scale_color_manual(values =c("#224573", "#4A6FA5", "#6B4F4F")) +labs(title ="Distribuições normais com diferentes parâmetros",subtitle ="Efeito da média e do desvio padrão na forma da curva",x ="x", y ="Densidade", color =NULL,caption ="Jennifer Luz Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"),legend.position ="bottom")
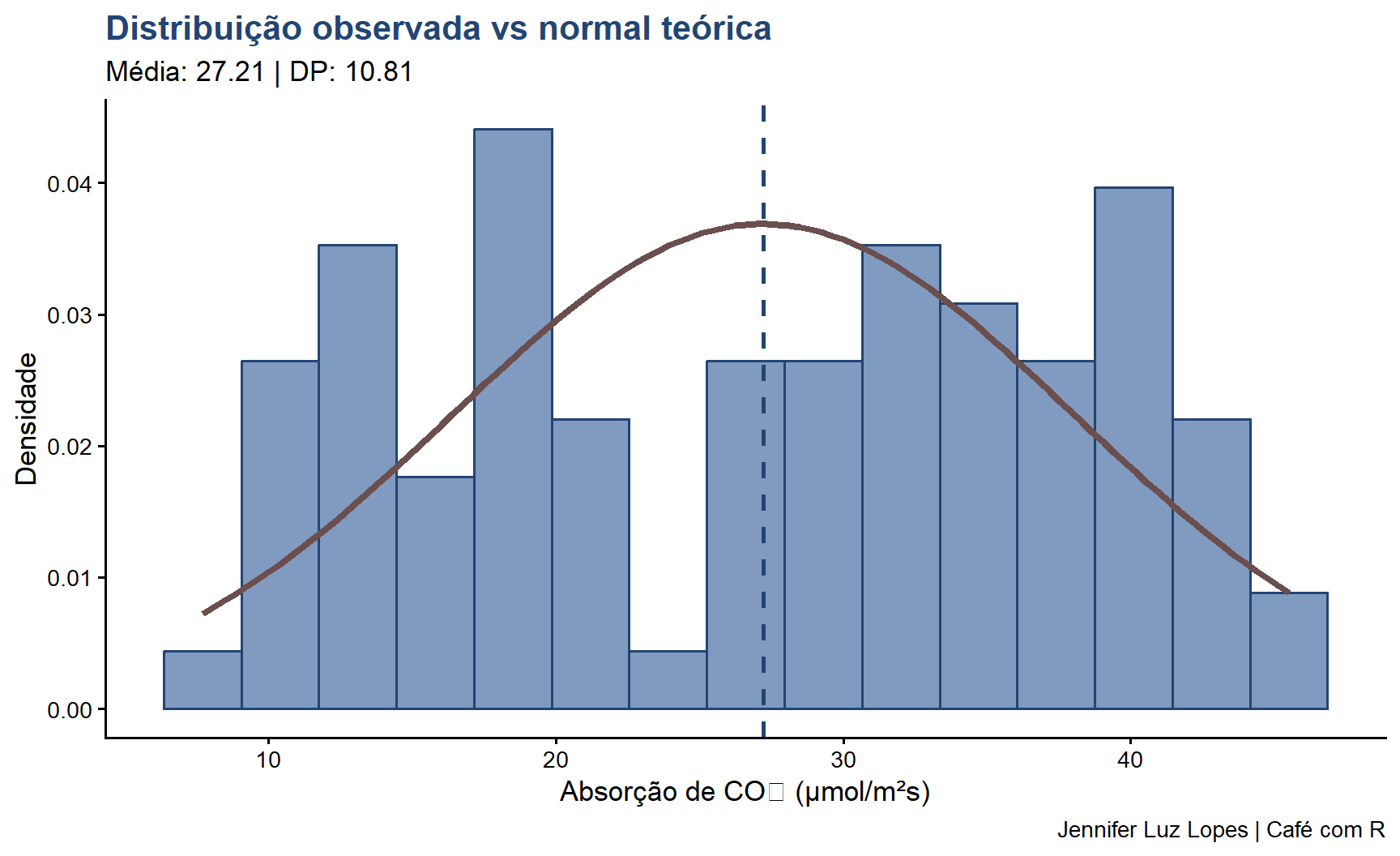
6.3 Por que testar normalidade?
A verificação da normalidade é necessária porque muitos testes paramétricos assumem que os dados (ou, mais precisamente, os resíduos do modelo) seguem distribuição normal. Violações severas desse pressuposto podem:
Distorcer os níveis de significância (p-valores incorretos)
Reduzir o poder estatístico
Invalidar intervalos de confiança
Mercado e pesquisa
Na prática, testa-se a normalidade dos resíduos do modelo, não dos dados brutos. Isso é especialmente verdadeiro para ANOVA e regressão. Testar apenas os dados originais antes de qualquer modelagem é um passo preliminar útil, mas insuficiente.
6.4 Métodos gráficos
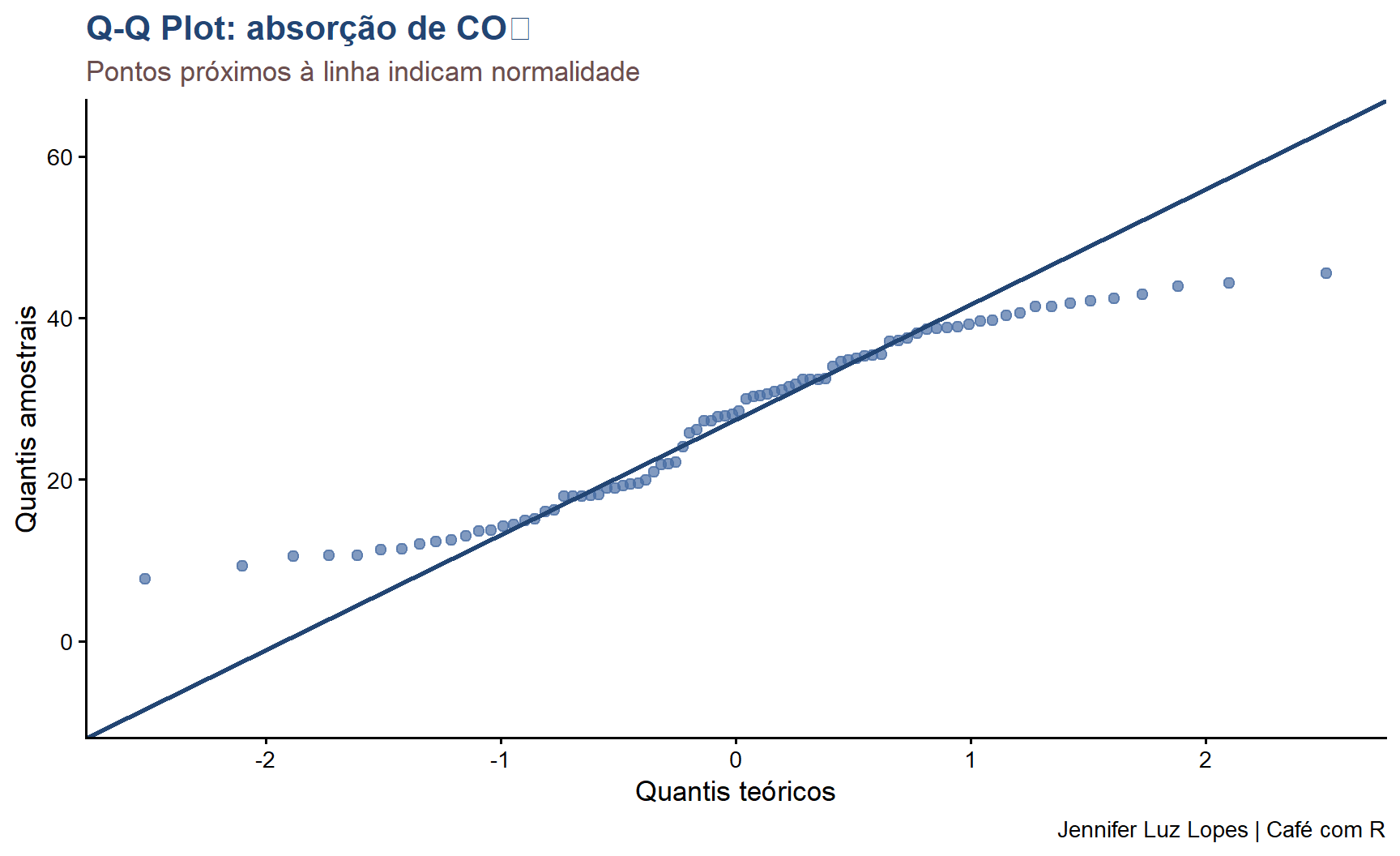
6.4.1 Q-Q Plot
O gráfico quantil-quantil (Q-Q plot) compara os quantis observados com os quantis esperados de uma distribuição normal teórica. Se os pontos seguirem de perto a linha de referência, os dados são consistentes com a normalidade.
ggplot(CO2, aes(sample = uptake)) +stat_qq(color ="#4A6FA5", size =2, alpha =0.7) +stat_qq_line(color ="#224573", linewidth =1) +labs(title ="Q-Q Plot: absorção de CO₂",subtitle ="Pontos próximos à linha indicam normalidade",x ="Quantis teóricos",y ="Quantis amostrais",caption ="Jennifer Luz Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"),plot.subtitle =element_text(color ="#6B4F4F"))
Use sempre o Q-Q plot junto com o teste numérico. Com amostras grandes, testes de normalidade tendem a rejeitar H₀ por desvios triviais e estatisticamente sem importância prática. Com amostras pequenas, o poder do teste é baixo, e pode não detectar desvios relevantes. O gráfico oferece uma avaliação mais informativa da magnitude do desvio.
6.6 Assimetria e curtose
6.6.1 Conceitos
Assimetria (skewness) mede o grau de simetria da distribuição:
Próximo de 0: simétrica
Positiva: cauda longa à direita (média > mediana)
Negativa: cauda longa à esquerda (média < mediana)
Curtose (kurtosis) mede o achatamento em relação à normal:
Mesocúrtica (≈ 0): similar à normal
Leptocúrtica (> 0): mais pontiaguda, caudas mais pesadas
Platicúrtica (< 0): mais achatada, caudas mais leves
skew_val <- DescTools::Skew(CO2$uptake)kurt_val <- DescTools::Kurt(CO2$uptake)data.frame(Medida =c("Assimetria", "Curtose"),Valor =round(c(skew_val, kurt_val), 4),Interpretacao =c(ifelse(abs(skew_val) <0.5, "Simétrica",ifelse(skew_val >0, "Assimétrica à direita", "Assimétrica à esquerda")),ifelse(abs(kurt_val) <0.5, "Mesocúrtica",ifelse(kurt_val >0, "Leptocúrtica", "Platicúrtica")))) |>kable(caption ="Medidas de forma da distribuição")
Medidas de forma da distribuição
Medida
Valor
Interpretacao
Assimetria
-0.1041
Simétrica
Curtose
-1.3483
Platicúrtica
Código fonte
---title: "Distribuições de probabilidade e normalidade"---```{r setup, include=FALSE}knitr::opts_chunk$set(echo=TRUE, warning=FALSE, message=FALSE, fig.align="center", fig.width=9, fig.height=5.5)library(tidyverse); library(nortest); library(DescTools); library(knitr)cores_cafe <-c("#224573", "#6B4F4F", "#4A6FA5", "#E5D3B3")data("CO2")```## Fundamentos de probabilidade**Probabilidade** é uma medida numérica da chance de ocorrência de um evento, variando de 0 (impossível) a 1 (certeza). Uma **distribuição de probabilidade** descreve como as probabilidades se distribuem entre os possíveis valores de uma variável aleatória.Para variáveis **contínuas**, usamos a **função densidade de probabilidade (PDF)**. Para variáveis **discretas**, usamos a **função massa de probabilidade (PMF)**.## A distribuição normalA distribuição normal (gaussiana) é a distribuição de probabilidade mais importante em estatística. Caracterizada por dois parâmetros, $\mu$ (média) e $\sigma$ (desvio padrão), sua função densidade é:$$f(x) = \frac{1}{\sigma\sqrt{2\pi}}\,e^{-\frac{1}{2}\left(\frac{x-\mu}{\sigma}\right)^2}$$### Propriedades fundamentais- **Simétrica** em torno de $\mu$: média = mediana = moda- **Forma de sino**: decresce suavemente em ambas as direções- **Área total = 1**: a probabilidade total de todos os eventos é 1- **Assintótica**: as caudas se aproximam do eixo horizontal sem tocá-lo### Regra empírica (68-95-99,7)Para qualquer distribuição normal:| Intervalo | Proporção dos dados ||-----------------------|---------------------|| $\bar{x} \pm 1s$ | ≈ 68% || $\bar{x} \pm 1{,}96s$ | ≈ 95% || $\bar{x} \pm 3s$ | ≈ 99,7% |### Por que a distribuição normal importa?1. **Ocorrência natural**: altura, peso, erros de medição, rendimentos agrícolas tendem a ser normalmente distribuídos2. **Teorema Central do Limite (TCL)**: a distribuição das médias amostrais converge para a normal conforme $n$ aumenta, independentemente da distribuição original3. **Fundamento dos testes paramétricos**: teste t, ANOVA e regressão linear assumem normalidade dos resíduos::: callout-note## ConceitoO TCL justifica o uso de testes paramétricos mesmo quando os dados individuais não são perfeitamente normais, desde que o tamanho amostral seja adequado (geralmente n ≥ 30 por grupo).:::### Padronização - Z-scoreQualquer variável normal pode ser convertida para a escala padrão (μ = 0, σ = 1):$$Z = \frac{X - \mu}{\sigma}$$O Z-score indica quantos desvios padrão um valor está acima (Z \> 0) ou abaixo (Z \< 0) da média. Valores com \|Z\|\> 3 são extremamente raros em distribuições normais.```{r normal_demo}# Demonstração: distribuição normal com diferentes parâmetrosx <-seq(-4, 4, length.out =300)df_normal <-data.frame(x =rep(x, 3),y =c(dnorm(x, 0, 1),dnorm(x, 0, 0.5),dnorm(x, 1, 1)),Curva =rep(c("N(0,1) - padrão","N(0, 0.5) - menor DP","N(1,1) - média deslocada"),each =300))ggplot(df_normal, aes(x = x, y = y, color = Curva)) +geom_line(linewidth =1.4) +scale_color_manual(values =c("#224573", "#4A6FA5", "#6B4F4F")) +labs(title ="Distribuições normais com diferentes parâmetros",subtitle ="Efeito da média e do desvio padrão na forma da curva",x ="x", y ="Densidade", color =NULL,caption ="Jennifer Luz Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"),legend.position ="bottom")```## Por que testar normalidade?A verificação da normalidade é necessária porque muitos testes paramétricos assumem que os dados (ou, mais precisamente, os **resíduos** do modelo) seguem distribuição normal. Violações severas desse pressuposto podem:- Distorcer os níveis de significância (p-valores incorretos)- Reduzir o poder estatístico- Invalidar intervalos de confiança::: callout-important## Mercado e pesquisaNa prática, testa-se a normalidade dos **resíduos** do modelo, não dos dados brutos. Isso é especialmente verdadeiro para ANOVA e regressão. Testar apenas os dados originais antes de qualquer modelagem é um passo preliminar útil, mas insuficiente.:::## Métodos gráficos### Q-Q PlotO gráfico quantil-quantil (Q-Q plot) compara os quantis observados com os quantis esperados de uma distribuição normal teórica. Se os pontos seguirem de perto a linha de referência, os dados são consistentes com a normalidade.```{r qq_plot}ggplot(CO2, aes(sample = uptake)) +stat_qq(color ="#4A6FA5", size =2, alpha =0.7) +stat_qq_line(color ="#224573", linewidth =1) +labs(title ="Q-Q Plot: absorção de CO₂",subtitle ="Pontos próximos à linha indicam normalidade",x ="Quantis teóricos",y ="Quantis amostrais",caption ="Jennifer Luz Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"),plot.subtitle =element_text(color ="#6B4F4F"))```### Histograma com curva normal teórica```{r histograma_normal}media_up <-mean(CO2$uptake)dp_up <-sd(CO2$uptake)ggplot(CO2, aes(x = uptake)) +geom_histogram(aes(y =after_stat(density)),bins =15,fill ="#4A6FA5",color ="#224573",alpha =0.7) +stat_function(fun = dnorm,args =list(mean = media_up, sd = dp_up),color ="#6B4F4F",linewidth =1.5) +geom_vline(xintercept = media_up,color ="#224573", linetype ="dashed", linewidth =1) +labs(title ="Distribuição observada vs normal teórica",subtitle =paste("Média:", round(media_up, 2),"| DP:", round(dp_up, 2)),x ="Absorção de CO₂ (μmol/m²s)",y ="Densidade",caption ="Jennifer Luz Lopes | Café com R") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"))```## Testes de normalidade### Shapiro-WilkO teste de Shapiro-Wilk é o mais recomendado para amostras de até 5.000 observações.**Hipóteses:**- H₀: os dados seguem distribuição normal- H₁: os dados não seguem distribuição normal**Critério:** se p-valor \> 0,05, não há evidência para rejeitar a normalidade.```{r shapiro}shapiro_resultado <-shapiro.test(CO2$uptake)data.frame(Estatistica_W =round(shapiro_resultado$statistic, 4),P_valor =round(shapiro_resultado$p.value, 4),Conclusao =ifelse(shapiro_resultado$p.value >0.05,"Não rejeita H0 (evidência de normalidade)","Rejeita H0 (evidência contra normalidade)")) |>kable(caption ="Teste de Shapiro-Wilk - absorção de CO₂")```### Shapiro-Wilk por grupo```{r shapiro_grupos}CO2 |>group_by(Type, Treatment) |>summarise(n =n(),Shapiro_W =round(shapiro.test(uptake)$statistic, 4),p_valor =round(shapiro.test(uptake)$p.value, 4),Normal =ifelse(shapiro.test(uptake)$p.value >0.05, "Sim", "Nao"),.groups ="drop") |>kable(caption ="Teste de Shapiro-Wilk por grupo experimental")```### Anderson-Darling e Kolmogorov-Smirnov```{r outros_testes}ad_resultado <- nortest::ad.test(CO2$uptake)ks_resultado <-ks.test(CO2$uptake, "pnorm",mean =mean(CO2$uptake),sd =sd(CO2$uptake))data.frame(Teste =c("Shapiro-Wilk", "Anderson-Darling", "Kolmogorov-Smirnov"),Estatistica =round(c(shapiro_resultado$statistic, ad_resultado$statistic, ks_resultado$statistic), 4),P_valor =round(c(shapiro_resultado$p.value, ad_resultado$p.value, ks_resultado$p.value), 4)) |>kable(caption ="Comparação dos testes de normalidade")```::: callout-tip## Boas práticasUse sempre o Q-Q plot junto com o teste numérico. Com amostras grandes, testes de normalidade tendem a rejeitar H₀ por desvios triviais e estatisticamente sem importância prática. Com amostras pequenas, o poder do teste é baixo, e pode não detectar desvios relevantes. O gráfico oferece uma avaliação mais informativa da magnitude do desvio.:::## Assimetria e curtose### Conceitos**Assimetria (skewness)** mede o grau de simetria da distribuição:- Próximo de 0: simétrica- Positiva: cauda longa à direita (média \> mediana)- Negativa: cauda longa à esquerda (média \< mediana)**Curtose (kurtosis)** mede o achatamento em relação à normal:- Mesocúrtica (≈ 0): similar à normal- Leptocúrtica (\> 0): mais pontiaguda, caudas mais pesadas- Platicúrtica (\< 0): mais achatada, caudas mais leves```{r assimetria_curtose}skew_val <- DescTools::Skew(CO2$uptake)kurt_val <- DescTools::Kurt(CO2$uptake)data.frame(Medida =c("Assimetria", "Curtose"),Valor =round(c(skew_val, kurt_val), 4),Interpretacao =c(ifelse(abs(skew_val) <0.5, "Simétrica",ifelse(skew_val >0, "Assimétrica à direita", "Assimétrica à esquerda")),ifelse(abs(kurt_val) <0.5, "Mesocúrtica",ifelse(kurt_val >0, "Leptocúrtica", "Platicúrtica")))) |>kable(caption ="Medidas de forma da distribuição")```