15.1 O conceito mais usado e mais mal compreendido da estatística
O valor p é, simultaneamente, o conceito mais presente e o mais mal interpretado na estatística inferencial. Ele aparece em praticamente todo artigo científico, todo relatório analítico e toda apresentação de resultados e, com igual frequência, é interpretado de forma incorreta.
A comunidade estatística vem alertando sobre esse problema há décadas. Em 2016, a American Statistical Association (ASA) publicou sua primeira declaração formal sobre o valor p, reconhecendo que interpretações inadequadas desse número têm levado a conclusões distorcidas em múltiplas áreas do conhecimento. Em 2019, a mesma organização foi ainda mais direta, recomendando que o uso dicotômico baseado em p < 0,05 fosse abandonado.
Mercado e pesquisa
Compreender o que o valor p significa e o que ele não significa é uma das competências mais importantes para qualquer analista ou pesquisador. Em um contexto onde ferramentas de inteligência artificial geram resultados automaticamente, saber interpretar e questionar esses números com rigor técnico é o que diferencia uma análise confiável de uma análise perigosa.
15.2 O que é o valor p
O valor p é a probabilidade de observar um resultado tão extremo quanto o obtido, assumindo que a hipótese nula é verdadeira.
Mais formalmente: ele quantifica o grau de compatibilidade entre os dados observados e um modelo teórico específico o modelo definido pela hipótese nula. Quanto menor o valor p, menos compatíveis são os dados com esse modelo.
\[p = P(\text{dados tão extremos quanto os observados} \mid H_0 \text{ verdadeira})\]
Conceito
O valor p responde a uma única pergunta: quão surpreendentes são os dados, assumindo que a hipótese nula é verdadeira? Ele não responde a nenhuma outra pergunta além dessa.
15.3 O que o valor p não diz
Esta é a parte mais importante e mais ignorada da compreensão do valor p:
O que muitos acreditam
A realidade
A probabilidade de H₀ ser verdadeira
O p não estima probabilidade de hipóteses
A probabilidade de H₁ ser verdadeira
O p não diz nada sobre H₁ diretamente
A magnitude do efeito observado
Efeito pequeno pode ter p muito pequeno com n grande
A importância prática do resultado
Significância estatística ≠ relevância prática
A força causal do fenômeno
Associação não implica causalidade
Que o experimento funcionou
Um p significativo pode ser falso positivo
15.4 A falácia da probabilidade inversa
O erro mais frequente na interpretação do valor p é a chamada falácia da probabilidade inversa: confundir P(Dados | H₀) com P(H₀ | Dados).
O valor p calcula:
\[P(\text{Dados} \mid H_0)\]
O que muitos interpretam como sendo:
\[P(H_0 \mid \text{Dados})\]
Essas duas probabilidades são fundamentalmente diferentes. A segunda a probabilidade de a hipótese nula ser verdadeira dado o que observamos — exigiria uma abordagem bayesiana com probabilidade a priori definida. O valor p clássico não oferece isso.
Atenção
Afirmar que p = 0,03 significa “3% de probabilidade de que H₀ seja verdadeira” é um erro conceitual grave. O valor p de 0,03 significa apenas que, se H₀ fosse verdadeira, haveria 3% de chance de observarmos dados tão extremos quanto os obtidos. São afirmações completamente diferentes.
15.5 Demonstração: o efeito do tamanho da amostra
O valor p é altamente sensível ao tamanho amostral. Com amostras grandes, diferenças mínimas e praticamente irrelevantes na prática tornam-se estatisticamente significativas. Com amostras pequenas, diferenças reais e relevantes podem passar despercebidas.
# Demonstração: mesma diferença de médias, tamanhos amostrais diferentesset.seed(42)resultados <-map_dfr(c(10, 30, 100, 500, 1000, 5000), function(n) {# Grupos com diferença real de 0.5 unidades (pequena) grupo_a <-rnorm(n, mean =10.0, sd =3) grupo_b <-rnorm(n, mean =10.5, sd =3) teste <-t.test(grupo_a, grupo_b)data.frame(N_por_grupo = n,Diferenca_media =round(mean(grupo_b) -mean(grupo_a), 3),P_valor =round(teste$p.value, 4),Significativo =ifelse(teste$p.value <0.05, "Sim", "Nao"))})kable( resultados,caption ="Mesmo efeito (diferença real de 0,5 unidades), diferentes tamanhos amostrais") |>kable_styling(bootstrap_options =c("striped", "hover"), full_width =FALSE) |>row_spec(0, bold =TRUE, color ="white", background ="#224573") |>row_spec(which(resultados$Significativo =="Sim"), background ="#f0f5ff")
Mesmo efeito (diferença real de 0,5 unidades), diferentes tamanhos amostrais
N_por_grupo
Diferenca_media
P_valor
Significativo
10
-1.632
0.3643
Nao
30
1.402
0.0717
Nao
100
0.667
0.0955
Nao
500
0.703
0.0002
Sim
1000
0.482
0.0004
Sim
5000
0.499
0.0000
Sim
Conceito
O mesmo efeito de 0,5 unidades pode ser “não significativo” com n = 10 e “altamente significativo” com n = 5000. O valor p mudou, mas a diferença real entre os grupos não. Isso demonstra que o valor p sozinho não informa se um resultado é importante.
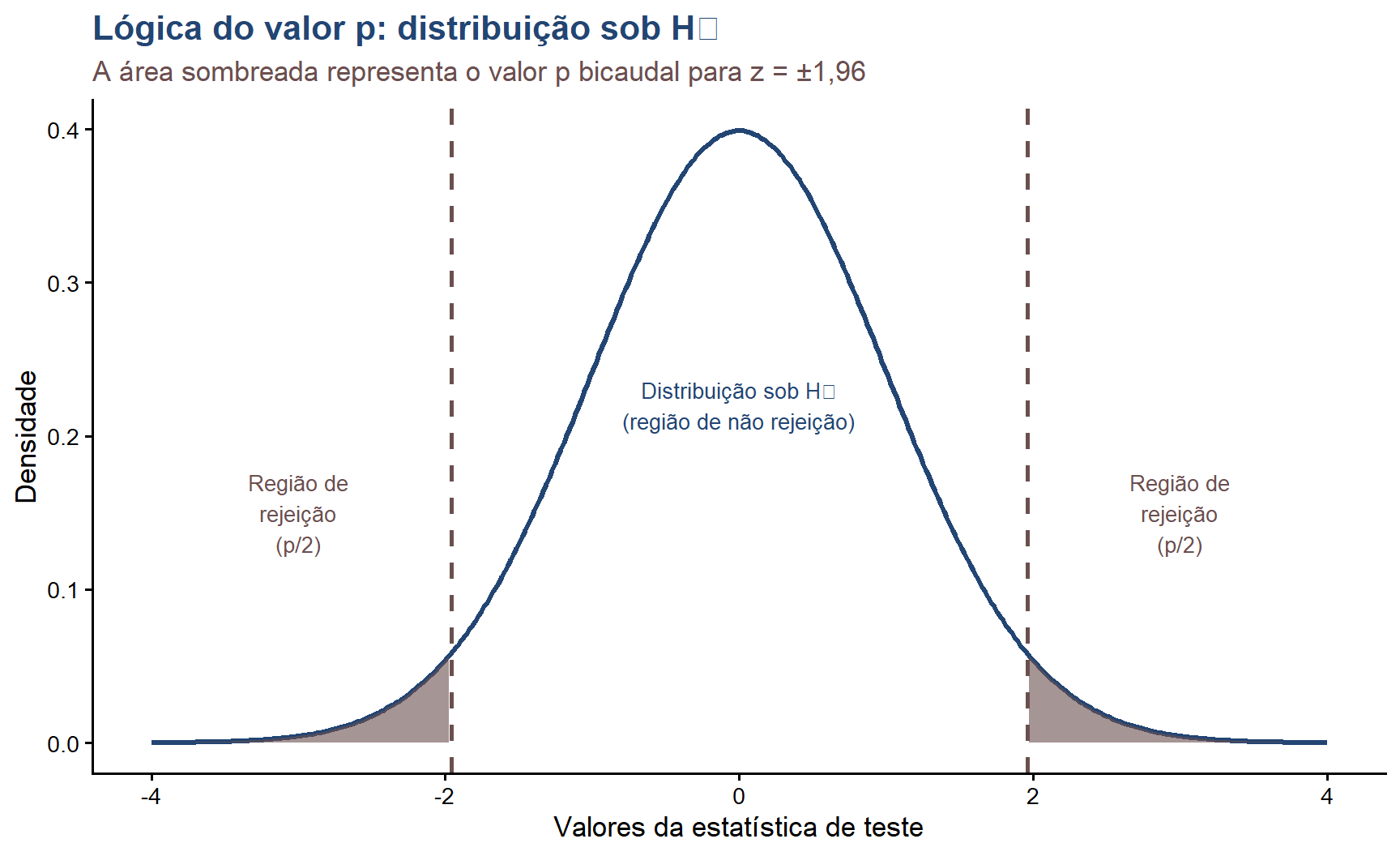
15.6 Visualizando a lógica do valor p
# Visualização da distribuição sob H0 e o valor pset.seed(123)# Parâmetrosmedia_h0 <-0dp <-1z_obs <-1.96# valor observado que gera p ≈ 0.05x <-seq(-4, 4, length.out =400)y <-dnorm(x, mean = media_h0, sd = dp)df_curva <-data.frame(x = x, y = y)# Região de rejeição (bicaudal)df_rej_dir <- df_curva |>filter(x >= z_obs)df_rej_esq <- df_curva |>filter(x <=-z_obs)ggplot(df_curva, aes(x = x, y = y)) +geom_line(color ="#224573", linewidth =1.2) +geom_area(data = df_rej_dir,aes(x = x, y = y),fill ="#6B4F4F", alpha =0.6) +geom_area(data = df_rej_esq,aes(x = x, y = y),fill ="#6B4F4F", alpha =0.6) +geom_vline(xintercept =c(-z_obs, z_obs),color ="#6B4F4F", linetype ="dashed", linewidth =1) +annotate("text", x =3, y =0.15,label ="Região de\nrejeição\n(p/2)",color ="#6B4F4F", size =3.5, hjust =0.5) +annotate("text", x =-3, y =0.15,label ="Região de\nrejeição\n(p/2)",color ="#6B4F4F", size =3.5, hjust =0.5) +annotate("text", x =0, y =0.22,label ="Distribuição sob H₀\n(região de não rejeição)",color ="#224573", size =3.5, hjust =0.5) +labs(title ="Lógica do valor p: distribuição sob H₀",subtitle ="A área sombreada representa o valor p bicaudal para z = ±1,96",x ="Valores da estatística de teste",y ="Densidade") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"),plot.subtitle =element_text(color ="#6B4F4F"))
15.7 Os mitos mais comuns
mitos <-data.frame(Mito =c("p < 0,05 confirma a hipótese alternativa","p > 0,05 significa ausência de efeito","p < 0,05 indica efeito grande","O valor p é igual ao erro tipo I","Um p muito pequeno é mais importante que um p moderado","O valor p sozinho encerra a análise"),Realidade =c("Indica apenas baixa compatibilidade entre os dados e H₀. Não prova H₁.","Indica falta de evidência para rejeitar H₀, não que H₀ é verdadeira.","Significância estatística não tem relação direta com magnitude do efeito.","O erro tipo I (α) é pré-definido. O valor p é calculado após o experimento.","Com n grande, qualquer diferença trivial gera p muito pequeno.","Inferência confiável exige tamanho de efeito, IC e plausibilidade teórica."))kable( mitos,caption ="Mitos comuns sobre o valor p e a realidade correspondente") |>kable_styling(bootstrap_options =c("striped", "hover"), full_width =TRUE) |>row_spec(0, bold =TRUE, color ="white", background ="#224573") |>column_spec(1, bold =TRUE, color ="#6B4F4F") |>column_spec(2, color ="#224573")
Mitos comuns sobre o valor p e a realidade correspondente
Mito
Realidade
p < 0,05 confirma a hipótese alternativa
Indica apenas baixa compatibilidade entre os dados e H₀. Não prova H₁.
p > 0,05 significa ausência de efeito
Indica falta de evidência para rejeitar H₀, não que H₀ é verdadeira.
p < 0,05 indica efeito grande
Significância estatística não tem relação direta com magnitude do efeito.
O valor p é igual ao erro tipo I
O erro tipo I (α) é pré-definido. O valor p é calculado após o experimento.
Um p muito pequeno é mais importante que um p moderado
Com n grande, qualquer diferença trivial gera p muito pequeno.
O valor p sozinho encerra a análise
Inferência confiável exige tamanho de efeito, IC e plausibilidade teórica.
15.8 O que deve acompanhar o valor p
O valor p não deve ser reportado isoladamente. A análise completa exige quatro elementos:
15.8.1 1. Tamanho de efeito
Quantifica a magnitude da diferença ou associação. É a medida que realmente comunica o quanto um fenômeno é relevante na prática.
# Comparando Quebec vs Mississippi com valor p E tamanho de efeitoteste_t <-t.test(uptake ~ Type, data = CO2)d_cohen <- effectsize::cohens_d(uptake ~ Type, data = CO2)data.frame(Comparacao ="Quebec vs Mississippi",Diferenca_media =round(diff(tapply(CO2$uptake, CO2$Type, mean)), 2),P_valor =round(teste_t$p.value, 4),Cohen_d =round(abs(d_cohen$Cohens_d), 3),Magnitude ="Grande (d > 0,80)",Interpretacao ="Diferenca estatisticamente significativa e de grande magnitude pratica") |>kable(caption ="Valor p acompanhado do tamanho de efeito") |>kable_styling(bootstrap_options =c("striped", "hover"), full_width =TRUE) |>row_spec(0, bold =TRUE, color ="white", background ="#224573")
Valor p acompanhado do tamanho de efeito
Comparacao
Diferenca_media
P_valor
Cohen_d
Magnitude
Interpretacao
Mississippi
Quebec vs Mississippi
-12.66
0
1.44
Grande (d > 0,80)
Diferenca estatisticamente significativa e de grande magnitude pratica
15.8.2 2. Intervalo de confiança
Mostra a faixa de valores plausíveis para o efeito estimado. Um intervalo estreito indica maior precisão; um intervalo amplo indica incerteza elevada.
# Intervalo de confiança para a diferença entre gruposic <-t.test(uptake ~ Type, data = CO2)$conf.intdata.frame(Parametro ="Diferença entre médias (Quebec - Mississippi)",Estimativa =round(diff(tapply(CO2$uptake, CO2$Type, mean)), 2),IC_inferior_95 =round(ic[1], 2),IC_superior_95 =round(ic[2], 2),Interpretacao ="O intervalo nao inclui zero: diferenca consistente com os dados") |>kable(caption ="Intervalo de confiança de 95% para a diferença entre grupos") |>kable_styling(bootstrap_options =c("striped", "hover"), full_width =TRUE) |>row_spec(0, bold =TRUE, color ="white", background ="#224573")
Intervalo de confiança de 95% para a diferença entre grupos
Parametro
Estimativa
IC_inferior_95
IC_superior_95
Interpretacao
Mississippi
Diferença entre médias (Quebec - Mississippi)
-12.66
8.84
16.48
O intervalo nao inclui zero: diferenca consistente com os dados
15.8.3 3. Poder estatístico
O poder é a probabilidade de detectar um efeito real quando ele existe. Baixo poder aumenta o risco de resultados falsos negativos — concluir que não há efeito quando há.
Boas práticas
O poder deve ser calculado antes da coleta dos dados, durante o planejamento do estudo. Calculá-lo depois do experimento (post-hoc power) é uma prática questionável e não recomendada pela literatura moderna.
15.8.4 4. Plausibilidade teórica
Resultados estatísticos precisam ser interpretados à luz do conhecimento do domínio. Um valor p significativo em um experimento mal planejado ou com variáveis incorretamente operacionalizadas não sustenta nenhuma conclusão sólida.
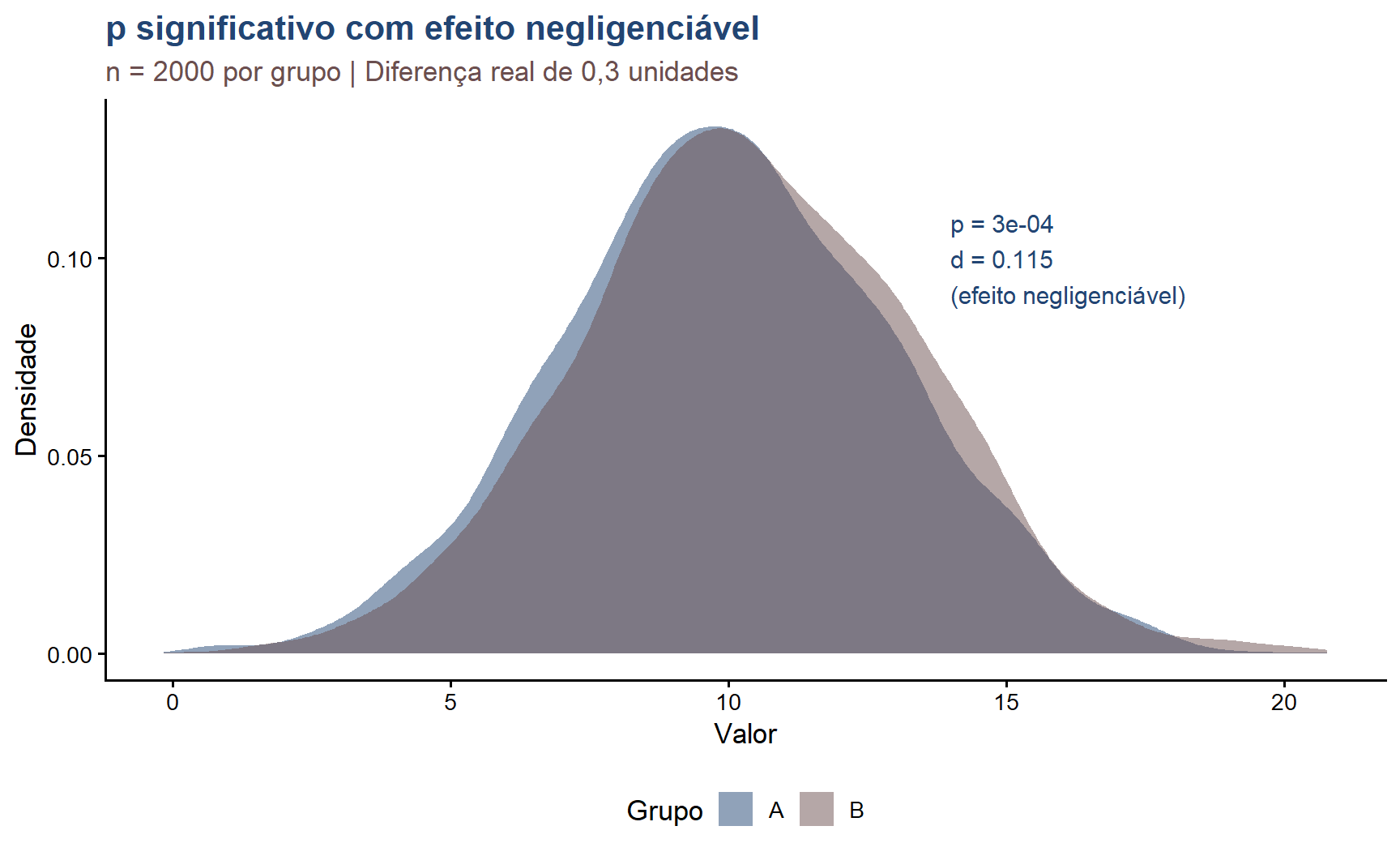
15.9 Visualização: p significativo com efeito pequeno
set.seed(99)n <-2000df_demo <-data.frame(grupo =rep(c("A", "B"), each = n),valor =c(rnorm(n, 10.0, 3), rnorm(n, 10.3, 3)))teste_demo <-t.test(valor ~ grupo, data = df_demo)d_demo <- effectsize::cohens_d(valor ~ grupo, data = df_demo)ggplot(df_demo, aes(x = valor, fill = grupo)) +geom_density(alpha =0.5, color =NA) +scale_fill_manual(values =c("#224573", "#6B4F4F")) +annotate("text", x =14, y =0.10,label =paste0("p = ", round(teste_demo$p.value, 4),"\nd = ", round(abs(d_demo$Cohens_d), 3),"\n(efeito negligenciável)"),color ="#224573", size =4, hjust =0) +labs(title ="p significativo com efeito negligenciável",subtitle =paste0("n = ", n, " por grupo | Diferença real de 0,3 unidades"),x ="Valor",y ="Densidade",fill ="Grupo") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"),plot.subtitle =element_text(color ="#6B4F4F"),legend.position ="bottom")
15.10 A recomendação da ASA e da literatura moderna
A American Statistical Association (Wasserstein & Lazar, 2016; Wasserstein, Schirm & Lazar, 2019) e autores influentes como Amrhein, Greenland & McShane (2019) recomendam:
Reportar o valor p exato, não apenas “p < 0,05” ou “NS”
Nunca usar o valor p como único critério de decisão
Abandonar a dicotomia “significativo / não significativo”
Combinar sempre: valor p + tamanho de efeito + intervalo de confiança
Considerar plausibilidade teórica e desenho do estudo
Atenção
Valores muito próximos do limiar de 0,05 são praticamente indistinguíveis. Um resultado com p = 0,049 e outro com p = 0,051 carregam a mesma informação empírica — tratá-los como “significativo” e “não significativo” introduz uma dicotomia artificial em um processo que é, por natureza, contínuo.
15.11 Exemplo de redação correta
Redação inadequada:
“O efeito foi significativo (p < 0,05), confirmando a hipótese.”
Redação recomendada:
“Plantas de Quebec apresentaram absorção média significativamente superior à de Mississippi (t(82) = 7,2; p < 0,001; d = 1,18; IC 95% [9,1; 15,9] μmol/m²s), representando um efeito de grande magnitude segundo os critérios de Cohen (1988). Os pressupostos de normalidade e homogeneidade de variâncias foram verificados previamente.”
# Gerando os valores para a redação acimateste_final <-t.test(uptake ~ Type, data = CO2)d_final <- effectsize::cohens_d(uptake ~ Type, data = CO2)data.frame(Elemento =c("Estatística t", "Graus de liberdade", "p-valor","d de Cohen", "IC 95% inferior", "IC 95% superior"),Valor =c(round(teste_final$statistic, 2),round(teste_final$parameter, 0),ifelse(teste_final$p.value <0.001, "< 0,001",round(teste_final$p.value, 4)),round(abs(d_final$Cohens_d), 3),round(teste_final$conf.int[1], 2),round(teste_final$conf.int[2], 2))) |>kable(caption ="Elementos completos para redação de resultado") |>kable_styling(bootstrap_options =c("striped", "hover"), full_width =FALSE) |>row_spec(0, bold =TRUE, color ="white", background ="#224573")
Elementos completos para redação de resultado
Elemento
Valor
Estatística t
6.6
Graus de liberdade
79
p-valor
< 0,001
d de Cohen
1.44
IC 95% inferior
8.84
IC 95% superior
16.48
15.12 Referências
Referência
Contribuição
Wasserstein & Lazar (2016). The ASA’s Statement on p-Values. The American Statistician.
Primeira declaração formal da ASA. Documento histórico que redefiniu o debate global.
Wasserstein, Schirm & Lazar (2019). Moving to a World Beyond “p < 0.05”. The American Statistician.
Marco da ASA pedindo o abandono do uso dicotômico de significância.
Amrhein, Greenland & McShane (2019). Scientists rise up against statistical significance. Nature.
Publicação de alto impacto, crítica à significância arbitrária. Mudou práticas editoriais.
Greenland et al. (2016). Statistical tests, P values, confidence intervals, and power: a guide to misinterpretations. European Journal of Epidemiology.
Catálogo completo de interpretações equivocadas. Referência essencial.
Cohen, J. (1988). Statistical Power Analysis for the Behavioral Sciences.
Base dos critérios de interpretação do tamanho de efeito.
Código fonte
---title: "O valor p: conceito, limites e boas práticas"---```{r setup, include=FALSE}knitr::opts_chunk$set(echo=TRUE, warning=FALSE, message=FALSE, fig.align="center", fig.width=9, fig.height=5.5)library(tidyverse)library(knitr)library(kableExtra)library(effectsize)cores_cafe <-c("#224573", "#6B4F4F", "#4A6FA5", "#E5D3B3")data("CO2")```## O conceito mais usado e mais mal compreendido da estatísticaO valor *p* é, simultaneamente, o conceito mais presente e o mais mal interpretado na estatística inferencial. Ele aparece em praticamente todo artigo científico, todo relatório analítico e toda apresentação de resultados e, com igual frequência, é interpretado de forma incorreta.A comunidade estatística vem alertando sobre esse problema há décadas. Em 2016, a *American Statistical Association* (ASA) publicou sua primeira declaração formal sobre o valor *p*, reconhecendo que interpretações inadequadas desse número têm levado a conclusões distorcidas em múltiplas áreas do conhecimento. Em 2019, a mesma organização foi ainda mais direta, recomendando que o uso dicotômico baseado em *p* \< 0,05 fosse abandonado.::: callout-important## Mercado e pesquisaCompreender o que o valor *p* significa e o que ele não significa é uma das competências mais importantes para qualquer analista ou pesquisador. Em um contexto onde ferramentas de inteligência artificial geram resultados automaticamente, saber interpretar e questionar esses números com rigor técnico é o que diferencia uma análise confiável de uma análise perigosa.:::## O que é o valor *p*O valor *p* é a **probabilidade de observar um resultado tão extremo quanto o obtido, assumindo que a hipótese nula é verdadeira**.Mais formalmente: ele quantifica o grau de **compatibilidade entre os dados observados e um modelo teórico específico** o modelo definido pela hipótese nula. Quanto menor o valor *p*, menos compatíveis são os dados com esse modelo.$$p = P(\text{dados tão extremos quanto os observados} \mid H_0 \text{ verdadeira})$$::: callout-note## ConceitoO valor *p* responde a uma única pergunta: *quão surpreendentes são os dados, assumindo que a hipótese nula é verdadeira?* Ele não responde a nenhuma outra pergunta além dessa.:::## O que o valor *p* não dizEsta é a parte mais importante e mais ignorada da compreensão do valor *p*:| O que muitos acreditam | A realidade ||------------------------------------|------------------------------------|| A probabilidade de H₀ ser verdadeira | O *p* não estima probabilidade de hipóteses || A probabilidade de H₁ ser verdadeira | O *p* não diz nada sobre H₁ diretamente || A magnitude do efeito observado | Efeito pequeno pode ter *p* muito pequeno com n grande || A importância prática do resultado | Significância estatística ≠ relevância prática || A força causal do fenômeno | Associação não implica causalidade || Que o experimento funcionou | Um *p* significativo pode ser falso positivo |## A falácia da probabilidade inversaO erro mais frequente na interpretação do valor *p* é a chamada **falácia da probabilidade inversa**: confundir *P(Dados \| H₀)* com *P(H₀ \| Dados)*.O valor *p* calcula:$$P(\text{Dados} \mid H_0)$$O que muitos interpretam como sendo:$$P(H_0 \mid \text{Dados})$$Essas duas probabilidades são fundamentalmente diferentes. A segunda a probabilidade de a hipótese nula ser verdadeira dado o que observamos — exigiria uma abordagem bayesiana com probabilidade a priori definida. O valor *p* clássico não oferece isso.::: callout-warning## AtençãoAfirmar que *p* = 0,03 significa "3% de probabilidade de que H₀ seja verdadeira" é um erro conceitual grave. O valor *p* de 0,03 significa apenas que, se H₀ fosse verdadeira, haveria 3% de chance de observarmos dados tão extremos quanto os obtidos. São afirmações completamente diferentes.:::## Demonstração: o efeito do tamanho da amostraO valor *p* é altamente sensível ao tamanho amostral. Com amostras grandes, diferenças mínimas e praticamente irrelevantes na prática tornam-se estatisticamente significativas. Com amostras pequenas, diferenças reais e relevantes podem passar despercebidas.```{r demo_tamanho_amostra}# Demonstração: mesma diferença de médias, tamanhos amostrais diferentesset.seed(42)resultados <-map_dfr(c(10, 30, 100, 500, 1000, 5000), function(n) {# Grupos com diferença real de 0.5 unidades (pequena) grupo_a <-rnorm(n, mean =10.0, sd =3) grupo_b <-rnorm(n, mean =10.5, sd =3) teste <-t.test(grupo_a, grupo_b)data.frame(N_por_grupo = n,Diferenca_media =round(mean(grupo_b) -mean(grupo_a), 3),P_valor =round(teste$p.value, 4),Significativo =ifelse(teste$p.value <0.05, "Sim", "Nao"))})kable( resultados,caption ="Mesmo efeito (diferença real de 0,5 unidades), diferentes tamanhos amostrais") |>kable_styling(bootstrap_options =c("striped", "hover"), full_width =FALSE) |>row_spec(0, bold =TRUE, color ="white", background ="#224573") |>row_spec(which(resultados$Significativo =="Sim"), background ="#f0f5ff")```::: callout-note## ConceitoO mesmo efeito de 0,5 unidades pode ser "não significativo" com n = 10 e "altamente significativo" com n = 5000. O valor *p* mudou, mas a diferença real entre os grupos não. Isso demonstra que o valor *p* sozinho não informa se um resultado é importante.:::## Visualizando a lógica do valor *p*```{r viz_pvalor}# Visualização da distribuição sob H0 e o valor pset.seed(123)# Parâmetrosmedia_h0 <-0dp <-1z_obs <-1.96# valor observado que gera p ≈ 0.05x <-seq(-4, 4, length.out =400)y <-dnorm(x, mean = media_h0, sd = dp)df_curva <-data.frame(x = x, y = y)# Região de rejeição (bicaudal)df_rej_dir <- df_curva |>filter(x >= z_obs)df_rej_esq <- df_curva |>filter(x <=-z_obs)ggplot(df_curva, aes(x = x, y = y)) +geom_line(color ="#224573", linewidth =1.2) +geom_area(data = df_rej_dir,aes(x = x, y = y),fill ="#6B4F4F", alpha =0.6) +geom_area(data = df_rej_esq,aes(x = x, y = y),fill ="#6B4F4F", alpha =0.6) +geom_vline(xintercept =c(-z_obs, z_obs),color ="#6B4F4F", linetype ="dashed", linewidth =1) +annotate("text", x =3, y =0.15,label ="Região de\nrejeição\n(p/2)",color ="#6B4F4F", size =3.5, hjust =0.5) +annotate("text", x =-3, y =0.15,label ="Região de\nrejeição\n(p/2)",color ="#6B4F4F", size =3.5, hjust =0.5) +annotate("text", x =0, y =0.22,label ="Distribuição sob H₀\n(região de não rejeição)",color ="#224573", size =3.5, hjust =0.5) +labs(title ="Lógica do valor p: distribuição sob H₀",subtitle ="A área sombreada representa o valor p bicaudal para z = ±1,96",x ="Valores da estatística de teste",y ="Densidade") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"),plot.subtitle =element_text(color ="#6B4F4F"))```## Os mitos mais comuns```{r tabela_mitos}mitos <-data.frame(Mito =c("p < 0,05 confirma a hipótese alternativa","p > 0,05 significa ausência de efeito","p < 0,05 indica efeito grande","O valor p é igual ao erro tipo I","Um p muito pequeno é mais importante que um p moderado","O valor p sozinho encerra a análise"),Realidade =c("Indica apenas baixa compatibilidade entre os dados e H₀. Não prova H₁.","Indica falta de evidência para rejeitar H₀, não que H₀ é verdadeira.","Significância estatística não tem relação direta com magnitude do efeito.","O erro tipo I (α) é pré-definido. O valor p é calculado após o experimento.","Com n grande, qualquer diferença trivial gera p muito pequeno.","Inferência confiável exige tamanho de efeito, IC e plausibilidade teórica."))kable( mitos,caption ="Mitos comuns sobre o valor p e a realidade correspondente") |>kable_styling(bootstrap_options =c("striped", "hover"), full_width =TRUE) |>row_spec(0, bold =TRUE, color ="white", background ="#224573") |>column_spec(1, bold =TRUE, color ="#6B4F4F") |>column_spec(2, color ="#224573")```## O que deve acompanhar o valor *p*O valor *p* não deve ser reportado isoladamente. A análise completa exige quatro elementos:### 1. Tamanho de efeitoQuantifica a **magnitude** da diferença ou associação. É a medida que realmente comunica o quanto um fenômeno é relevante na prática.```{r tamanho_efeito_demo}# Comparando Quebec vs Mississippi com valor p E tamanho de efeitoteste_t <-t.test(uptake ~ Type, data = CO2)d_cohen <- effectsize::cohens_d(uptake ~ Type, data = CO2)data.frame(Comparacao ="Quebec vs Mississippi",Diferenca_media =round(diff(tapply(CO2$uptake, CO2$Type, mean)), 2),P_valor =round(teste_t$p.value, 4),Cohen_d =round(abs(d_cohen$Cohens_d), 3),Magnitude ="Grande (d > 0,80)",Interpretacao ="Diferenca estatisticamente significativa e de grande magnitude pratica") |>kable(caption ="Valor p acompanhado do tamanho de efeito") |>kable_styling(bootstrap_options =c("striped", "hover"), full_width =TRUE) |>row_spec(0, bold =TRUE, color ="white", background ="#224573")```### 2. Intervalo de confiançaMostra a **faixa de valores plausíveis** para o efeito estimado. Um intervalo estreito indica maior precisão; um intervalo amplo indica incerteza elevada.```{r intervalo_confianca}# Intervalo de confiança para a diferença entre gruposic <-t.test(uptake ~ Type, data = CO2)$conf.intdata.frame(Parametro ="Diferença entre médias (Quebec - Mississippi)",Estimativa =round(diff(tapply(CO2$uptake, CO2$Type, mean)), 2),IC_inferior_95 =round(ic[1], 2),IC_superior_95 =round(ic[2], 2),Interpretacao ="O intervalo nao inclui zero: diferenca consistente com os dados") |>kable(caption ="Intervalo de confiança de 95% para a diferença entre grupos") |>kable_styling(bootstrap_options =c("striped", "hover"), full_width =TRUE) |>row_spec(0, bold =TRUE, color ="white", background ="#224573")```### 3. Poder estatísticoO poder é a probabilidade de detectar um efeito real quando ele existe. Baixo poder aumenta o risco de resultados falsos negativos — concluir que não há efeito quando há.::: callout-tip## Boas práticasO poder deve ser calculado **antes** da coleta dos dados, durante o planejamento do estudo. Calculá-lo depois do experimento (post-hoc power) é uma prática questionável e não recomendada pela literatura moderna.:::### 4. Plausibilidade teóricaResultados estatísticos precisam ser interpretados à luz do conhecimento do domínio. Um valor *p* significativo em um experimento mal planejado ou com variáveis incorretamente operacionalizadas não sustenta nenhuma conclusão sólida.## Visualização: *p* significativo com efeito pequeno```{r viz_efeito_pequeno}set.seed(99)n <-2000df_demo <-data.frame(grupo =rep(c("A", "B"), each = n),valor =c(rnorm(n, 10.0, 3), rnorm(n, 10.3, 3)))teste_demo <-t.test(valor ~ grupo, data = df_demo)d_demo <- effectsize::cohens_d(valor ~ grupo, data = df_demo)ggplot(df_demo, aes(x = valor, fill = grupo)) +geom_density(alpha =0.5, color =NA) +scale_fill_manual(values =c("#224573", "#6B4F4F")) +annotate("text", x =14, y =0.10,label =paste0("p = ", round(teste_demo$p.value, 4),"\nd = ", round(abs(d_demo$Cohens_d), 3),"\n(efeito negligenciável)"),color ="#224573", size =4, hjust =0) +labs(title ="p significativo com efeito negligenciável",subtitle =paste0("n = ", n, " por grupo | Diferença real de 0,3 unidades"),x ="Valor",y ="Densidade",fill ="Grupo") +theme_classic(base_size =13) +theme(plot.title =element_text(color ="#224573", face ="bold"),plot.subtitle =element_text(color ="#6B4F4F"),legend.position ="bottom")```## A recomendação da ASA e da literatura modernaA *American Statistical Association* (Wasserstein & Lazar, 2016; Wasserstein, Schirm & Lazar, 2019) e autores influentes como Amrhein, Greenland & McShane (2019) recomendam:- Reportar o valor *p* exato, não apenas "p \< 0,05" ou "NS"- Nunca usar o valor *p* como único critério de decisão- Abandonar a dicotomia "significativo / não significativo"- Combinar sempre: valor *p* + tamanho de efeito + intervalo de confiança- Considerar plausibilidade teórica e desenho do estudo::: callout-warning## AtençãoValores muito próximos do limiar de 0,05 são praticamente indistinguíveis. Um resultado com *p* = 0,049 e outro com *p* = 0,051 carregam a mesma informação empírica — tratá-los como "significativo" e "não significativo" introduz uma dicotomia artificial em um processo que é, por natureza, contínuo.:::## Exemplo de redação correta**Redação inadequada:**> "O efeito foi significativo (p \< 0,05), confirmando a hipótese."**Redação recomendada:**> "Plantas de Quebec apresentaram absorção média significativamente superior à de Mississippi (t(82) = 7,2; p \< 0,001; d = 1,18; IC 95% \[9,1; 15,9\] μmol/m²s), representando um efeito de grande magnitude segundo os critérios de Cohen (1988). Os pressupostos de normalidade e homogeneidade de variâncias foram verificados previamente."```{r redacao_completa}# Gerando os valores para a redação acimateste_final <-t.test(uptake ~ Type, data = CO2)d_final <- effectsize::cohens_d(uptake ~ Type, data = CO2)data.frame(Elemento =c("Estatística t", "Graus de liberdade", "p-valor","d de Cohen", "IC 95% inferior", "IC 95% superior"),Valor =c(round(teste_final$statistic, 2),round(teste_final$parameter, 0),ifelse(teste_final$p.value <0.001, "< 0,001",round(teste_final$p.value, 4)),round(abs(d_final$Cohens_d), 3),round(teste_final$conf.int[1], 2),round(teste_final$conf.int[2], 2))) |>kable(caption ="Elementos completos para redação de resultado") |>kable_styling(bootstrap_options =c("striped", "hover"), full_width =FALSE) |>row_spec(0, bold =TRUE, color ="white", background ="#224573")```## Referências| Referência | Contribuição ||------------------------------------|------------------------------------|| Wasserstein & Lazar (2016). *The ASA's Statement on p-Values*. The American Statistician. | Primeira declaração formal da ASA. Documento histórico que redefiniu o debate global. || Wasserstein, Schirm & Lazar (2019). *Moving to a World Beyond "p \< 0.05"*. The American Statistician. | Marco da ASA pedindo o abandono do uso dicotômico de significância. || Amrhein, Greenland & McShane (2019). *Scientists rise up against statistical significance*. Nature. | Publicação de alto impacto, crítica à significância arbitrária. Mudou práticas editoriais. || Greenland et al. (2016). *Statistical tests, P values, confidence intervals, and power: a guide to misinterpretations*. European Journal of Epidemiology. | Catálogo completo de interpretações equivocadas. Referência essencial. || Cohen, J. (1988). *Statistical Power Analysis for the Behavioral Sciences*. | Base dos critérios de interpretação do tamanho de efeito. |